<![CDATA[Tomasz Pluskiewicz]]>2021-03-28T12:28:09+00:00http://t-code.pl/Octopress<![CDATA[Hydra and SHACL - part 2 - IRI Templates]]>2020-12-28T00:00:00+00:00http://t-code.pl/blog/2020/12/hydra-shacl-templatesIn the previous post I presented the simplest functionality of loading remote form contents by having SHACL property shape reference a Hydra Core collection.
In the second part I will extend that example to create a form with multiple connected dropdowns, where each one is only populated when other(s) have been selected, which is a common scenario seen in (web) applications.
TL;DR; can I see it working?
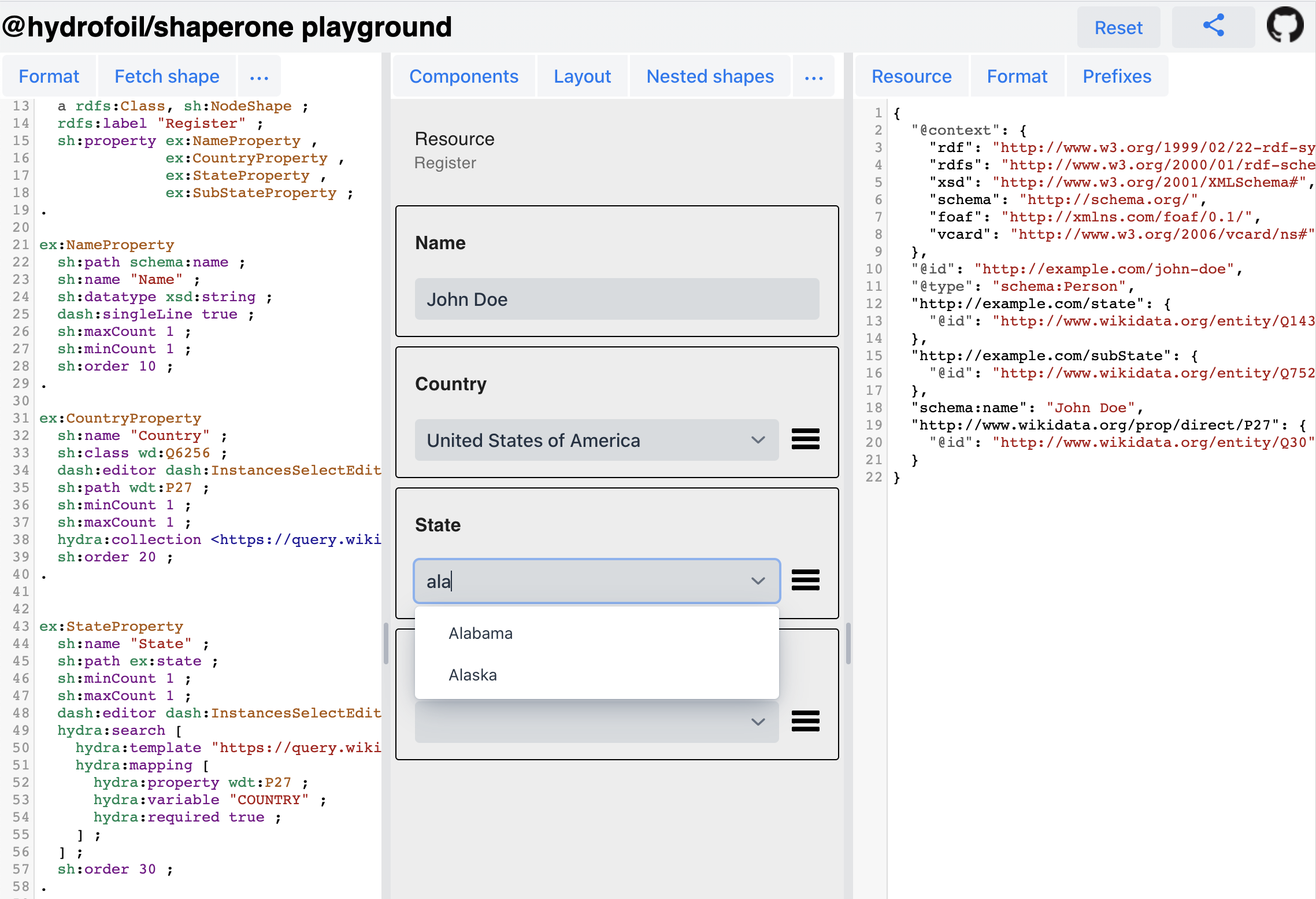
The screenshot below links to Shaperone Playground which implements the ideas described in the subsequent paragraphs.
Filtering collections with Hydra
In addition to hydra:collection, the Hydra Core vocabulary comes with another general-purpose property hydra:search. Unlike most predicates which would link to another resource, identified by a concrete URI, its objects are instances of URI Templates, defined by RFC6570.
For example, let’s have a “State collection” resource which returns country’s first-level administrative division. It would come with a search template so that clients can construct filtered URIs:
The client must provide template values to a Hydra library which will return a URI fit for dereferencing. This is called expansion by the RFC6570. A Hydra client will take a graph node with values being attached to that node using the hydra:property as defined by the template and match those property/object pairs to the template variables.
Here’s an example of such a template variable model, where JSON-LD @context has been constructed from the hydra:mapping, although the JSON keys may be irrelevant for the expansion if the implementation only relies on the actual graph data.
A form can be generated for agents (usu. humans) to create an instance of such a graph
Use the created graph to expand a template
Now, a form in such a scenario could simply be used to filter a collection for display, but I propose to short-circuit it back into the form itself so that the filtered collection, when dereferenced, provides values for other fields.
The Person shape above has two properties. The first will generate a dropdown with a selection of countries as described in the first Hydra+SHACL post. The second, while it’s also going to render a dropdown, will not be populated until a country is selected (hydra:required true).
The glue here is matching property shared between sh:path of the upstream field and hydra:property of the downstream’s search template. In other words, when the form’s graph node receives the value for the schema:addressCountry predicate, the “states” will be loaded.
Less APIs, more Web Standards!
Again this time, the playground example does not “talk” to an actual API but instead runs SPARQL queries encoded into query string parameters of Wikidata’s query endpoint. The trick is to replace a URI of the variable with a URI Template placeholder. Just gotta make sure that the braces are not percent-encoded.
Loading cities is slightly more complicated, accounting for deeper graphs where a state is the root and also various types of cities recognised by Wikidata.
Tried as I might, the cities query does not work for every country. United States, Germany and Poland are fine. On the other hand, for Colombia and Australia it finds no cities at all. Queries for Australian cities are also surprisingly slow…
It is not important for the example, but I would be curious to learn from a Wikidata expert how it can be improved.
]]><![CDATA[Hydra and SHACL - a perfect couple - part 1]]>2020-12-20T00:00:00+00:00http://t-code.pl/blog/2020/12/hydra-shacl-interoperabilityHydra Core is a community-driven specification for describing hypermedia APIs in a machine readable form so that client applications can discover the resources at runtime. On its own, however, it is not expressible enough to describe any arbitrary resource representation.
SHACL, or Shapes Constraint Language, on the other hand is a beautifully extensible schema-like language which offers great power and flexibility in describing graph data structures.
Combined, they provide a complete solution for building hypermedia applications driven by RDF.
TL;DR; I want some action!
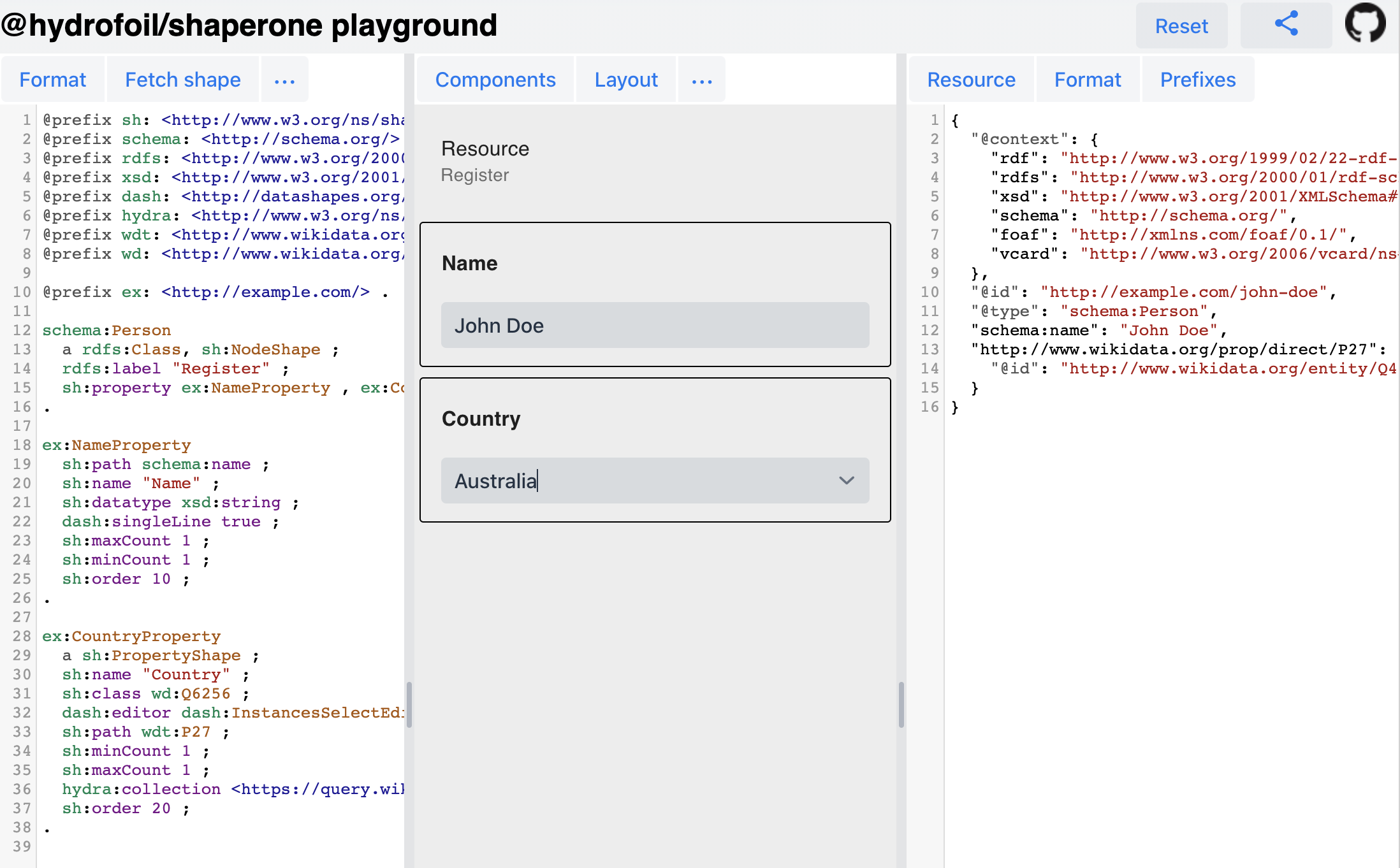
Click the image to open Shaperone Playground, which demonstrates a working example of a form generated from a SHACL shape which dynamically loads Wikidata resources using SPARQL.
At the bottom of this post you will see how to configure shaperone this way.
Hydra HTTP request descriptions
The Hydra vocabulary defines a term hydra:Operation which represents a HTTP request which a server advertises as being supported by specific resources, either by a specific instance or entire class of resources.
For the sake of this blog post, let’s consider a hypothetical API which describes a registration request:
The above snippet, excerpt from the API’s Documentation resource, declares that the clients will come across a collection of users (rdf:type <UserCollection>) against which a POST request will be possible to create a new resource. That operation will require a representation of the <User> class.
While Hydra Core vocabulary does have a basic set of terms which can describe the user class, it may not be enough to cater for rich client-server interactions as well as a UI building block. Neither will be RDFS, and OWL, although quite powerful, is a little complex and seriously lacks tooling support and widespread recognition.
Enter, SHACL.
Using SHACL to describe API payloads
SHACL is another RDF vocabulary, which describes data graphs by constraining properties and values of precisely targeted nodes in an RDF graph. It could be used to complement the API Documentation graph above by providing the required shape of instances of the <User> class. This is easiest done by turning it into an implicitly targetedsh:NodeShape.
In this example let’s require users to provide exactly one name (using schema:name) and exactly one country of citizenship (using said Wikidata property P27)
Hopefully this is quite self-explanatory so far.
The objects of sh:property require that any instance of <User> have exactly one of each property, declared using sh:path. That is achieved using sh:minCount and sh:maxCount
Name must be at least 3 characters long string
Country must be an instance of Wikidata Country class wd:Q6256
Exactly one country is allowed
sh:order is a UI hint for organising inputs in a form
dash:singleLine is a form builder hint which ensures that the text field does not allow line breaks (ie. no <textarea>)
dash:editor instructs the form builder to create an input component with a selection of instances of the desired RDF type
SHACL is quite wonderful in that shapes are useful for many purposes. Check the SHACL Use Cases and Requirements note for a host of examples. In the presented scenario, a rich client can use to dynamically produce a form to have users input the data, and the server will run validations to check that requests payloads satisfy the SHACL constraints.
There is one piece missing however: where do the Country instances come from? 🤨
Circling back to Hydra
Out of the box, a SHACL processor would assume that any instances would be part the Data Graph. While this works for validation inside of TopBraid it is not feasible to build a browser application that way. For example, at the time of writing there are 171 instances of Country in Wikidata. Combined with a multitude of labels in various languages that is total of over 40 thousand triples. It’s hardly a good idea to push that proactively to the client up front.
Instead, I propose to connect the Shape back with the API using Hydra Core term hydra:collection. It is defined modestly:
Collections somehow related to this resource.
It also does not have and rdfs:range or rdfs:domain making it a good candidate for linking a property shape directly with its data source:
By adding this property a UI component can load the countries by dereferencing a hydra:Collection whose representation would look somewhat like this:
APIs are dead; Long live (Linked Data) APIs!
So far the subject was APIs, but the web is more than just servers returning data, even if that data is RDF. You see, the hypothetical registration form above actually references a third party dataset, which is Wikidata. All of this data is already on the web and use standard formats. By using a simple SPARQL query the countries can be fetched directly from their source; without even adding the /countries resource to your API. Heck, the client appication would not need a dedicated API at all!
123456789101112131415161718
# wd: and wdt: are implicitly added by wikidata's SPARQL endpointprefixhydra:<http://www.w3.org/ns/hydra/core#>CONSTRUCT{?colahydra:Collection.?colhydra:member?country.?countryrdfs:label?label.}WHERE{BIND(<https://example.app/countries>as?col)# wdt:P31 - "instance of"# wd:Q6256 - "country"?countrywdt:P31wd:Q6256;rdfs:label?label# only request labels in a handful of languages# to dramatically reduce response sizeFILTER(lang(?label)IN('en','de','fr','pl','es'))}
This query can be directly encoded in a URL to GET the countries and populate a dropdown component. You can see that in the playground, mentioned in the beginning.
All possible thanks to web standards 🤘
Implementation notes
Shaperone makes building a Hydra-aware form like this easy:
12345678910111213
import*ascomponentsfrom'@hydrofoil/shaperone-wc/NativeComponents'// OR import * as components from '@hydrofoil/shaperone-wc-material/components'// OR import * as components from '@hydrofoil/shaperone-wc-vaadin/components'// OR roll your own rendering componentsimport*asconfigurefrom'@hydrofoil/shaperone-wc/configure'import{instancesSelector}from'@hydrofoil/shaperone-hydra/components'// register UI component which will do the renderingconfigure.components.pushComponents(components)// add Hydra extension to dash:InstancesSelectEditorconfigure.editors.decorate(instancesSelector.matcher)configure.components.decorate(instancesSelector.decorator())
The @hydrofoil/shaperone-hydra package extends the default behaviour to have hydra:collection dereferenced rather than looking for the instance data locally.
Next steps
In future posts I will present how to:
use Hydra descriptions to find collections without hydra:collection directly
hydra:search URI Templates can be used to:
create forms with dependent fields, so that users first select a country which is then used to narrow down a selection of country’s secondary administrative division and so on POST
improve performance by filtering resources on the data source
]]><![CDATA[Why RDF is struggling - the case of R2RML]]>2020-07-24T00:00:00+00:00http://t-code.pl/blog/2020/07/rdf-struggling-case-of-r2rmlIn 2012 I started my .NET implementation of R2RML and RDB to RDF Direct mapping which I called r2rml4net. It never reached the maturity it should have but now, 8 years later, I have little choice but to polish it and use it for converting my database to triples. A task I had originally intended but never really completed.
Why is it significant? Because all those years later the environment around R2RML as a standard is almost as broken, incomplete and sad as it was when I started. Let’s explore that as an example of what is wrong with RDF in general.
Update July 31st, 2020
It has been brought to my attention that Morph is in fact actiavely maintained. I’ve updated it’s details and evaluation.
Intro. What is R2RML?
R2RML and Direct Mapping are two complementary W3C recommendation (specifications) which define language and algorithm respectively which are used to transform relation databases into RDF graphs. The first is a full blown, but not overly complicated RDF vocabulary which lets designers hand-craft the way in which relational tables are converted into RDF. Individual columns are either directly converted into values (taking their respective database types into consideration) or used within simple templates to produce compound values as literals, blank node and literal alike.
Direct Mapping is a simpler approach, often using R2RML internally as the mapping model, which creates an automatic mapping from any given relational database into triples. The specification defines way in which tables, rows and values are meant to map into triples. It can be either executed standalone and then the resulting RDF would be refined, or an R2RML document can be produced so that it can be fine-tune before the actual transformation happens.
Complementary to these two specs there are a two sets of test cases which can be exercised by implementors claiming compatibility and advertised at a central RDB2RDF implementation report page hosted by W3C.
Related to R2RML, there is also a newer specification RML.io which extends it into supporting also other sources like XML and CSV.
Why is it important?
I had an interesting twitter exchange recently where I tried to present arguments why applying RDF selectively, without really using it in every layer of the application architecture is problematic.
You need to look at the big picture, entire stack of a single or multiple applications
Polyglot persistence becomes a burden if you convert JSONs and relational data into RDF all the time
If RDF is not your programming model then you're in for pain
In that case JSON-LD got the bashing but the bottom like here is that when building an application using RDF technologies it is worth using it in all software components. From the user interface all the way to the database. This is the only way which prevents constant tension between graph and non-graph models, such as the mentioned issue where JSON-LD hides the graphy nature of data. It is a similar problem which haunted software where relation data model is mapped into object complex models. For that I recommend the classic blog post by Jeff Atwood titled Object-Relational Mapping is the Vietnam of Computer Science
R2RML should be an important tool in the toolkit of any Semantic Web development team as it aims to provide an effective way for migrating existing datasets stored in SQL silos into RDF. This can be done by performing a one-time conversion as mentioned above but an alternative approach some take is running the mapping on-demand, for example by translating SPARQL queries into SQL without ever persisting the converted triples.
You could think that surely, over the years we should have grown a vibrant ecosystem around this cornerstone piece of technology. Well, think again…
My humble requirements
For my use case I have simple requirements. I need to perform a fairly simple mapping of a handful of tables into quads. That is, I want to partition the dataset into named graphs, mostly in a graph-per-entity fashion. Pretty standard as R2RML goes.
My database is Azure SQL so MS SQL has to be supported.
I expect also ease of use. Preferably a standalone CLI, easily installed and usable on CI.
R2RML implementations in the wild
The first logical place to look for R2RML software should be the Implementation Report. It lists 8 implementations, 4 out of which implement both R2RML and Direct mapping:
The listing is clearly not actively maintained (last updated in August 2012) so one would also try searching so the latest and greatest. Here’s what I found:
Let’s take a closer look to check if they present a viable option. I’m only interested in R2RML so that eliminates D2RQ and SWObjects dm-materialize but let’s check them out either way.
Of the RML implementations, CARML and RocketRML do not support SQL data source and SDM-RDFizer does not support SQL Server. That leaves RMLMapper.
Finally, there are a bunch of commercial products which incorporate R2RML and other kinds of mappings and migrations from other data sources to semantic graphs. Names like Stardog or Anzo which are aimed at big corporate settings. They often don’t have free versions, require adopting their entire, integrated environment and cost big buck.
RDF-RDB2RDF
Version
0.008
😕
Last release
2013-09-20
👎
Installation
Perl package manager
👎
Developed by
individual
The project page is rather developer-centric. An INSTALL file linked in an Other files section says
Installing RDF-RDB2RDF should be straightforward.
If you have cpanm, you only need one line:
1
% cpanm RDF::RDB2RDF
Looks simple, but I have no idea about PERL and cpanm. There is also a README file but the usage instructions are rather uninformative. I think this is only a library. Even if this gets the job done, there is no way I’m learning PERL for this 🙄
XSPARQL
While the address linked from the implementation report is now dead, a quick google reveals its new home on GitHub.
Version
1.1.0
👍
Last release
2019-02-04
👍
Installation
.jar download
🙄
Developed by
Company (?)
The R2RML feature is not well advertised but found in the wiki under Working with RDBMS SQL
Configuration is provided using a .properties file. Awkward but doable. Unfortunately the project does not show an example of how to set it up.
ultrawrap
Developed by
Company
The linked company Capsenta redirects to https://data.world and appears to be a commercial product. There is also a Community tier of what seems to be a SaaS offering.
Not sure about this one.
db2triples
Version
2.2
👍
Last release
2019-08-02
👍
Installation
Build with maven
👎
Developed by
Company
This one looks promising. Sadly, it appears that the sources have to be built manually. No thank you. On the other hand the format parameter can be one of 'RDFXML', 'N3', 'NTRIPLES' or 'TURTLE' so I guess no named graphs? 😢
D2RQ
Version
0.8.1
👌
Last release
2012-06-22
👎
Installation
Download from d2rq.org
🙄
Developed by
Universities
Anyway, only Direct Mapping and unmaintained but if it works, it works…
SWObjects dm-materialize
❌ It’s dead Jim
OpenLink Virtuoso
Version
7.2
✨
Last release
2018-08-15
👍
Installation
Dedicated installers + a plugin
😕
Developed by
Company
Virtuoso is a well-known name in the RDF space. It is a commercial product and a triple store. Support for R2RML comes as an add-on and the overall setup looks super complicated and not at all standalone 👎. Sorry
morph
Version
3.12.5
👌
Last release
2019-09-20
👌
Installation
JAR download
👌
Developed by
Company
Much outdated in the original 2012 implementation report, it turns out that Morph has seen much activity since and has been developed by a commercial company. Java-style setup using a JAR download and the awkward .properties file but definitely something to try out.
Ontop
Version
4.0-rc1
👌
Last release
2020-06-08
🎉
Installation
JAR download
👌
Developed by
University
Ontop is mainly a Virtual Graph endpoint, like d2rq, but comes with a CLI command materialize which takes a R2RML mapping graph and serializes the resulting triples to a file.
Unfortunately, at the time of writing named graphs are not supported. The project is very actively maintained and that might change very soon.
Karma
Version
2.4
👍
Last release
2020-06-03
✨
Installation
GUI? mvn exec:java?
😕
Developed by
University
Another super active but also quite complex tool. An installation page shows how to install a GUI tool. The README gives examples of commands running Maven within a clone of the original repository. Maybe I’m missing something but it does look like it falls into “easy of use” category.
To do it justice, this definitely looks super useful as a
an information integration tool that enables users to quickly and easily integrate data from a variety of data sources
as advertised in the repo. Not what I’m looking for though.
d2rq/r2rml-kit
Version
N/A
👎
Last update
2019-06-19
✨
Installation
scripts in repository
😕
Developed by
Individual (?)
r2rml-kit is an offshoot of D2RQ, based on its abandoned develop branch
r2rml-kit is currently in pre-alpha stage.
Not only is it pre-alpha, it is also not really maintained. Too bad…
chrdebru/r2rml
Version
N/A
👎
Last update
2020-04-13
👌
Installation
build sources
👎
Developed by
Individual
Another Java project which fails to even provide a pre-built JAR. This one has at least seen some development recent time and claims to support quad output formats. Maybe worth a go.
RMLMapper
Version
4.8.1
✨
Last release
2020-07-03
🎉
Installation
docker run
👌
Developed by
University
The last RML implementation looks promising too. Actively maintained, supports SQL server, outputs quads, uses modern tooling. A definite candidate for success.
Summary
For such a crucial piece of software it’s quite disappointing to see in what state the environment is and how little it has changed since 2012 when I first had a look at R2RML.
The old implementations died off or became commercial products. C’est la vie.
The surviving ones on the other hand mostly fail to provide a usable package. Why should I be interested in running Maven or even manually downloading a JAR to run. Where is the simplicity of package managers effortless installation one can find in JavaScript (npm i -g hypothetical-r2rml) or the latest .NET (dotnet tool install -g hypothetical-r2rml). Once installed it should simply create a global executable to run the transformation.
And why are so many poorly documented? Again, I can mostly speak of JS and .NET ecosystems and there are plenty of examples of beautiful, detailed documentation pages and guides. How is it possible that most of those above fail on that front.
Maybe I’m being unfair about that last point. Much software is poorly documented and I have been guilty of that myself in the past but for the RDF community at large it should be critical to provide working, well documented software in order for semantic technologies to achieve any wider recognition.
Finally, I would have said in the past that universities are part of the problem and the Semantic Web has been long viewed as academic and impractical. It pleases me to see that but of the above, the more recent uni-managed packages actually stand out as being more modern and better maintained overall. 👍
And I have not even looked at test coverage but I do not dare.
Coming next
In the end, it’s still a little disappointing how limited the choice seems for someone looking for an unimposing but functional R2RML solution. In the two lists above I gathered 16 potential candidates out of which only a handful remain:
XSPARQL (config is going to be a trial & error thing)
db2triples (only if the docs are inaccurate and named graphs are supported)
morph
Ontop (no named graph but deserves a closer look)
chrdebru/r2rml
RMLMapper
I initially intended to give more details about each of the promising implementation in this post but I decided that I should look in more detail and actually try running and comparing those most promising implementations to see if they can actually deliver. In a subsequent post I will take my mappings and try processing them with the 5 tools I selected.
]]><![CDATA[Testing APIs Hypermedia-style]]>2019-06-27T12:15:00+00:00http://t-code.pl/blog/2019/06/testing-hypermedia-apiOne would expect the task of (REST) API testing to be a well-researched subject. After all, REST has been formulated over a
decade ago and the number of APIs being built keeps growing exponentially. Yet, it seems that the art of testing APIs hasn’t
changed much from the approaches used in testing RPC-style APIs or non-API code.
In this post I’d like to propose a different approach to defining and executing tests of a truly RESTful, hypermedia-driven API.
Recap. What is a Hypermedia-driven API?
The Hypermedia REST constraint, originally called Hypermedia As The Engine of Application State by Roy Fielding, is probably
easiest to grasp through the maxim follow your nose. It means that a client should base the subsequent state changes
(server requests) solely on information gathered from previously received resource representations. The information
available depends on the media type being used. Different media types may provide a different degree of hypermedia support.
The facets have been gathered by Mike Amundsen in his H Factor measurement model.
For example, the simple but popular media type HAL supports links, which lets clients follow them without a priori
knowledge about specific URLs. All they need to know is a link relation name, and look for that link in the resource
representation. What’s more, the links can appear and disappear in said representations based on resource’s state or the
user’s permissions. An adaptive client should only follow links which are present at the given moment.
More sophisticated media types would also provide forms, such as <form> in HTML, which allow clients to perform requests
with methods different than GET to change the state of resources.
Problem with existing testing tools
There are multiple popular tools used for testing APIs. Some of the names include Postman, REST Assured,
Karate or SoapUI. Each one of these tool has their respective strengths and characteristics, but they
all share a similar flaw: they revolve around URI of individual resources and test them in isolation. While it may sound
good from a unit testing perspective, it’s pretty obvious that API tests will always be integration tests. Focusing on a resource
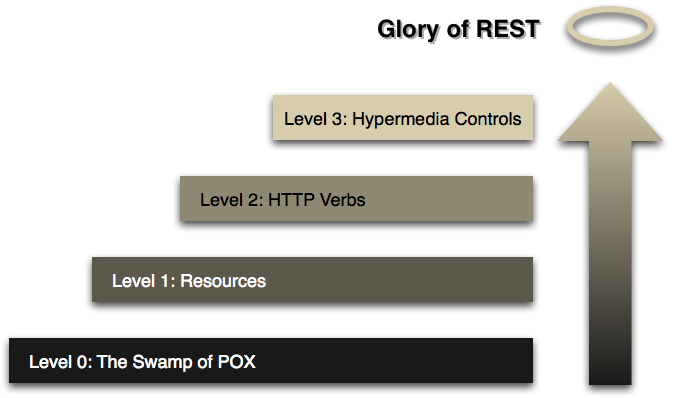
identifier prevents the tests from taking advantage of rich hypermedia controls. Those cannot be easily tested, even if
the API under test uses a hypermedia media type. Such tests will mostly only reach level 3 of Richardson Maturity Model.
Test by following your nose
To overcome this problem I propose a different approach to building an API test suite. Most importantly, the test executor
must act just like a hypermedia-aware client. It should only ever follow links and submit forms found in received resource
representations. It also should never begin testing from any random URL because a REST API should only ever advertise just
a single stable home URL.
Thus, a test scenario must begin with requesting the aforementioned initial resource and making its way through other
representations via links and forms. I call this What you GET is what you test which would be abbreviated WYGIWYT,
taking after the ancient web development acronym.
WYGIWYT DSL
To make this approach I propose a completely new DSL, or domain-specific language, which can capture the nature of
transitioning between resource representations.
The most basic building block would be to define expected hypermedia controls at the root of a test definition. Such top-level
(or ambient) declaration would be eagerly executed whenever it is encountered in any resource.
For example, the below snippet could instruct the runner to follow every author
link and assert that it responds with a 200 HTTP status code:
123
Follow Link author every time {
Expect status code 200
}
In more complex scenarios, such as involving creating and removal of resources, a nested structure would help build a
sequence of related requests. Here’s how I imagine a complete workflow:
123456789101112131415161718192021222324
With class Person {
Expect Identifier [person]
With Form addFriend {
Submit application/x-www-form-urlencoded
(
newFriendId=/id/of/friend/
) {
Expect Status Code 201
Expect Header Location [newFriend]
Follow [newFriend] {
Expect Property friend /id/of/friend/
Expect Property friendOf [person]
With Form delete {
Submit {
Expect Status Code 204
}
}
}
}
}
}
This is just a pseudocode draft but the intention is to keep a clear structure which should read like natural language.
This example should be interpreted as:
When you find a Person resource, remember its identifier as person
If it contains an addFriend form, submit it with a given body
Check that a resource has been created and GET it by following the Location header
Verify that it has been created with certain properties
Use the delete form to remove that resource
Some notes on the DSL
It is clear that media types are not made equal. They also use various names for similar concepts (eg. form vs operation
vs action). While the initial version will focus on Hydra, the DSL should become customizable to
allow plug-in support for other specific media types.
Individual runners would also need to implement media type-specific ways for discovering the hypermedia.
The DSL will then be compiled to a JSON structure, which shall simplify the implementation of runners.
Next steps
We are starting to build the DSL with Eclipse Xtext and generators with Xtend. Those are very mature
DSL tools, probably the most sophisticated out there.
There seems to be just a handful of research papers and even less development going on around testing hypermedia APIs.
The problem with research papers is also that most of them don’t really produce concrete, runnable tools. The only one that
does from those mentioned below, is apparently not available for download.
A fairly recent library exists, called Hyperactive. It crawls an API to check
that the links are not broken between resources. Unfortunately it is essentially just that, a simple crawler.
A similar paper has been published in 2010 titled Connectedness testing of RESTful web-services
by Sujit Chakrabarti of Bangalore. The approach the authors take is quite similar to the proposed DSL. The downside,
shown also in the papers I mention below, is that it seems to be tightly coupled to URL structures and specific implementation
details, such as HTTP methods. Our approach differs in that it should rely more on the hypermedia control rather than
out-of-band information.
Another, quite promising paper is Model-Based Testing of RESTful Web Services Using UML Protocol State Machines
by Pedro Victor Pontes Pinheiro, André Takeshi Endo, Adenilso da Silva Simão, published in 2013. Instead of DSL, UML diagrams
are used to build the interaction paths. Other than that it seems that the proposed tool (I could not find the code) has
some good features, including coverage. The presented approach does not seem suffer from the problem of hardcoding URLs, etc.
Finally, 2017’s Towards Property-Based Testing of RESTful Web Services by Pablo Lamela Seijas, Huiqing Li and
Simon Thompson proposes an Erlang-based DSL. Unfortunately the resulting syntax is hardly welcoming, and the approach in
general is again in opposition to hypermedia controls. The shown examples are limited to JSON and revolve around URIs and
hardcoded HTTP methods.
]]><![CDATA[Writing storybook inlined with markdown]]>2018-08-11T12:15:00+00:00http://t-code.pl/blog/2018/08/storybook-markdown-inlineWhat good are stories if you’re not actually telling them? Storybook is a fantastic and versatile tool
to create runnable showrooms of elements written in a number of javascript libraries. It presents live
examples of components but lack in plain old storytelling - the prose. There are addons but they are not
presentable enough (addon-notes) or do not support all targets (addon-info).
Here I present a different approach, using lit-html and a markdown custom element. It works
well with my web components but hopefully could be adapted to handle any supported framework.
What are you talking about?
Even if the addon-notes could be easily styled ot addon-info worked with something else than only React, I
kind of think that putting the textual description of the addons panel make them seem irrelevant. An
afterthought. Instead, I’d rather it was a prominent part of each story. Sharing space with the live examples.
Only then the stories create a complete documentation pages and not just a set of naked elements you can
prod.
As you see, the actual story will be rendered within the formatted text
Rendering markdown
The interesting bit you may notice above is the md import which in fact is a template string tag function.
Here’s my lit-html implementation which wraps all static portions with a markdown rendering custom element
and combines them with the stories. It also handles non-template values so that it’s possible to inject
not only stories but also any other content dynamically into the documentation template.
Since I’m creating web components, it came natural to me to compose my documentation pages using lit-html
and a 3rd party custom element to render markdown. There are a number to choose from. I chose
<zero-md> which works well and I simply have used it before. Any other should be good too as long as it
can be be fed with markdown directly from HTML (as opposed to external .md files).
To load it I use polymer-webpack-loader. I tried adding the element to preview-head.html but it
somehow interferes with the polyfill. Bundling with webpack is good enough. Installing from bower could also
be a faux pas but hey, it works.
Room for improvement
At the point of writing the latest release of lit-html cannot render inside <template> tag. This should
change soon but for now I build the <zero-md> elements by hand.
Now that I think about it, the markdown rendering element could be replaced with simple JS-based
transformation. The element however comes with styling capabilities and by default imports GitHub rendering
styles.
Another current limitation of lit-html is that import { html } from 'lit-html cannot be mixed with
import { html } from 'lit-html/lib/lit-extended. It’s also about to change soon but something to keep in
mind.
A lit-html-based implementation probably would not work with React but it should be simple enough to compose
the content with jsx instead in a similar fashion.
]]><![CDATA[Maintaining documentation of JS library in lockstep with code]]>2018-05-06T18:20:00+00:00http://t-code.pl/blog/2018/05/js-living-docsI’ve long been aware of GitBook.com as a way to easily author documentation pages. What I did not know before
was that it also comes with a robust tooling for building the book locally and building as a static website.
Works great with GitHub Pages, albeit needing some specific setup to run from the /docs folder. In itself
though it may just be a good-looking alternative to other static page generators or documentation builders.
The difference however is the abundance of plugins, and one plugin in particular useful for documenting JS
code.
Setting up GitBook for GitHub pages
The GitBook toolchain has some setting which collide with how GitHub Pages expect you to organize your
repository. It’s nothing really problematic but impossible to change so you may as well be aware of how
to work with both together.
The first step is to prepare your repository to host both code and documentation. See this gitbook
to set up and install the command line tool.
Next, initialize a folder for the markdown sources of your documentation pages. I called that folder gitbook.
You can do it by running the command below.
1
gitbook init ./gitbook
You will also have to create a book.json configuration file pointing to the root of you book
123
{"root":"./gitbook"}
To test your GitBook locally you can run gitbook serve. Note that you will want to ignore a folder called
_book which is where the site is being generated for serving locally.
Once you’ve created some pages you build static documentation pages by running gitbook build. In the latest
version of GitBook CLI there is no setting to control the output folder and it will by default write the
output to the same _book folder. GitHub pages however expects the static pages to be served from a /docs
folder, which also cannot be changed. The only way to make both happy is to pass an output folder to the
build command. I added a complete command to my package.json.
This will take the sources from the root, as set up in book.json and write HTML to /docs. That should be,
just commit and push to publish your book on github.io.
Writing live snippets…
As mentioned before, GitBook itself is nice but the real great feature are numerous plugins, and one plugin
in particular: RunKit.
As its page states
RunKit is Node prototyping
It lets anyone create actual live snippets running node with any package available on npmjs.org registry.
It is actually possible to load any particular version, similarly to how you would install a specific version
with Yarn on NPM. Additionally it also wraps the snippets in an async function so that they can use the
await keyword instead of promises and renders a nice output for JS objects or HTML. Go ahead and see what
happens when you paste the snippet below snippet on runkit.com.
The ability to request any chosen version from NPM has one great implication. You can have the embedded
snippets always use a version matching the state of the repository. Instead of keeping a concrete number
in the runkit snippets, GitBook lets the authors create variables and inject them in their pages. Here’s
my config file:
12345
{"variables":{"version":"0.4.0-a5"}}
It defines a variable which I use in all my snippets so that they use the most recent version of my
library:
At this point there are simple steps to follow in order to always have the documentation using the right
version:
Change my code as usual
Publish next version to NPM
Update documentation
Bump the GitBook version variable
Build GitBook
Commit, tag and push repository
This way the online documentation always point to the most recent version but anyone checking out any tag
will be able to run the documentation as it existed at that point in time. And the code examples will use
the matching version from NPM!
Bonus: documentating multiple versions of the library
With a simple modification of these steps one could also keep multiple versions of the documentation,
targeting multiple versions of the library.
Build the book to a /docs/latest instead
Whenever you’re ready to tag you repository, make a copy of that folder to one named after the
version. For example /docs/v0.9, /docs/1.0, /docs/2.0, etc.
This way you will keep all past versions documented alongside the latest on
github.io/my-lib/v0.9, github.io/my-lib/v1.0 and github.io/my-lib/v2.0 respectively.
See it in action
Go ahead and check Alcaeus’ documentation pages at https://alcaeus.hydra.how
to see live examples published using the RunKit plugin.
]]><![CDATA[Hidden gem - easiest way to manage SqlLocalDB]]>2018-05-06T18:20:00+00:00http://t-code.pl/blog/2018/05/hidden-gem-sqllocaldbSQL Server LocalDB is not something new to me. The ability quickly to run, and destroy a database without much
hassle has been great aid in running test code which was meant to target a live SQL database. That said, it
wasn’t always without any hassle at all. I tried various tools which make it a bit easier than the command line
tool but nothing was perfect. Until recently, when I’ve discovered the humbly named NuGet package which
is as simple as it gets.
What is SQL LocalDB?
SQL Server LocalDB is a simple utility which ships with recent SQL Server editions (Express included). It let’s
you create a temporary, yet full-featured database. It may not seem like much, after all it’s possible with SQL
server itself to connect to master database, run create database and initialize it according to your needs.
The difference is though that one doesn;t have to manage two connections and doesn’t have to share credentials
to the master database or require Windows Authentication. Instead, an automatic instance is always available
locally. However to run a fully isolated database it is necessary to create it, start it and eventually destroy.
It is also possible to use a magic Server=(LocalDB)\MSSQLLocalDB connection string (also supports
attaching to file db). Personally though I’ve had mixed results with using a connection string. To be honest
I never fully understood how it’s supposed to be used ;).
Managed code to the rescue
There are a number of C# libraries which aim at simplifying the use of SQL LocalDB. In a previous project
we had integration tests run against a temporary database created in code yet the steps still followed the
same patter showed above:
Create LocalDB instance
Start the instance
Get its connection string
Create a ADO.NET connection
Stop the databse
Destroy it
I had a feeling back then that it’s not as friendly as it could get and just this week, while migrating an
old open source library of mine to .NET Standard I discovered what has to be the most
hassle-free solution.
SqlLocalDb.nupkg
Turns out it’s not new but it somehow slipped under my radar the last time I was looking.
It’s really dead simple to use it:
1234567891011
using(vardatabase=newLocalDatabase()){using(varconnection=database.GetConnection()){connection.Open();// do your thing// run your tests// or whatever}}
No need to manage the LocalDB instances at all. The library will make sure that it’s created and then get
rid of it once the LocalDatabase object is disposed. It’s as convenient as it gets.
]]><![CDATA[How to set up storybook to play nice with lit-html-based element]]>2018-03-26T21:15:00+00:00http://t-code.pl/blog/2018/03/storybook-with-lit-html-and-polymer-3I’d like to share a few tips which might help you set up @storybook/polymer with a JS-only elements. The
core issue was importing a base mixin class from Polymer 3, which causes the default babel configuration to
transpile into an unusable bundle.
Background
In my code I have a base class which uses Polymer’s PropertiesChanged mixin to offload handling attributes
and properties:
1234567
import{PropertiesChanged}from'@polymer/polymer/lib/mixins/properties-changed';exportdefaultclassLitAnyBaseextendsPropertiesChanged(HTMLElement){/* rest of my code */}
There is not build step and the code works great when bundled using webpack in an actual web application.
The issue with storybook
Unfortunately this does not work of out the box with Storybook for Web Components (maybe it will be renamed
after all). By design the storybook generates a shell index.html which loads web components polyfill and
custom-elements-es5-adapter.js. The latter requires that all ES6 be transpiled into ES5. Otherwise any of
the code would not work in older browsers which do not support classes.
The thing is though that it’s an all or nothing approach. Without the adapter all code must be ES6, as per
custom elements v1 spec. With the adapter on other hand it is not possible to mix the two approaches. So what
happens when Storybook generates its bundle? My code gets transpiled as expected:
12345678910111213
varLitAnyBase=function(_PropertiesChanged){_inherits(LitAnyBase,_PropertiesChanged);functionLitAnyBase(){_classCallCheck(this,LitAnyBase);var_this=_possibleConstructorReturn(this,(LitAnyBase.__proto__||Object.getPrototypeOf(LitAnyBase)).call(this));return_this;}/* the ugly ES5 continues here */}
_PropertiesChanged however would still be as ES6 class (because it comes from node_modules?) even though
they both end up in the very same bundle. The effect is a sight many web component developers probably witnessed:
TypeError: Class constructor PropertiesChanged cannot be invoked without ‘new’
Solution
It had taken me a few hours of futile experiments with various webpack and babel configs until my colleague
Kamil helped me out. Turns out all it took was a minimal babel setup.
Initial setup
First things first, here are the steps I used to set up Storybook in my repository, similar to the
Slow start guide
Next create .babelrc as follows. It is interesting that es2015 in not required to be called out
explicitly but it has to be installed as a dependency nonetheless.
123
{"presets":["react","env","stage-0"]}
Then also yarn add -D babel-plugin-transform-decorators-legacy.
Finally the simplest webpack config must be added next to storybooks config file.
It will cause all of node_modules to be loaded by babel which can take significantly more to build, but
hey, at least now my storybook works!
Update for Storybook 4
I recently updated to Storybook 4.0.alpha.9. It seems to be working fine despite some benign errors showing
in the console. It didn’t “just work” though. Right after upgrade I was running into similar issues with bundling.
To fix that the babel-loader needs a minor tweak:
]]><![CDATA[Visual Studio must-have - Open Command Line (and Babun)]]>2017-10-25T08:00:00+00:00http://t-code.pl/blog/2017/10/vs-must-have-open-command-lineI’ve been using the Open Command Line
by Mads Kristensen for several months now. Recently I’ve finally figured out how to have it open Babun and
decided to share.
The extension is quite simple. It adds a menu item to folders in Solution Explorer and a shortcut which will open a new
terminal window. By default it’s Alt+Space, which I haven’t felt like changing.
Not only does it open that console, it will actually set the working directory based on the open file or selected item in
Solution Explorer, whichever is focused.
Default settings include Developer Command Prompt but most importantly it let’s you set up a custom terminal to run.
Setting up with Babun the right way
In the past I had already set up Open Command Line to open Babun but it opened an ugly cygwin window which I didn’t like.
It made me use the extension sparingly. With proper setup however I use it all the time.
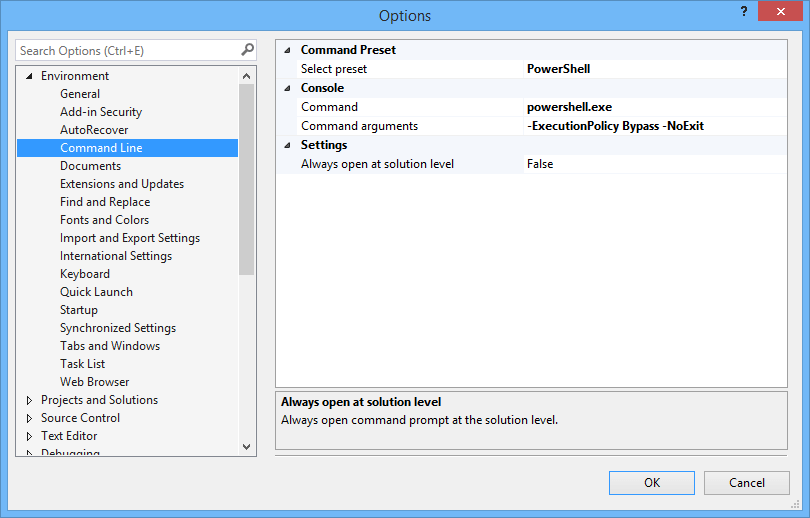
To set it up go to Tools -> Optiona -> Command Line and input these values
]]><![CDATA[Building UI like LEGO (with string template literals)]]>2017-08-29T22:45:00+00:00http://t-code.pl/blog/2017/08/lego-templates-with-template-literalsSome time ago I experimented and wrote about building composable UI using Polymer and <template> was my
main building block. I used it to declare building blocks for my pages which I would dynamically interchange depending on
the displayed content. Unfortunately I’ve hit a number of roadblocks but I think I’ve just recently found a solution.
Just last week I attended the third Polymer Summit in Copenhagen where Justin Fagnani showed his
newest experiment: lit-html. You should definitely watch his presentation:
Why is this important? Apparently, the next version of Polymer won’t directly use the <template> tag. Instead, it will
be 100% JS. Yes, you heard correctly. No more <dom-module>:
As you see, instead of HTML+JS, there is only code. Looks more like React+JSX, doesn’t it? It sparked heated discussions
at the conference, on Polymer’s Slack channel and on Twitter.
At this stage though, the above template() method returns a static HTML string, which is then injected into a HTML
template and later stamped into the element’s shadow root. Justin’s lit-html, akin to a number of earlier libraries takes
this one step further, thanks to the properties of JavaScript’s template literals (the backtick strings, duh!).
Template literals
Here’s an example how a basic component could use lit-html
This is has all advantages of JS: scoping, syntax highlighting and suggestions and the ability to compose a template from
multiple other literals. This opens completely new possibilities where one can create decorator components or override
extensible points of parent element. Features which were very cumbersome with plain <template> tags.
But most importantly, lit-html is FAST.
lit-html is not Virtual DOM… but better
By design, the template literal can be prefixed with a tag (did you open the MDN link above?).
A tag, in this case called html is actually a function with a simple signature:
1
html(strings,...values);
The strings will be an array of all static parts and the values are the interpolated expressions. The trick is that
whenever the render function is called with the same template it will actually be just one instance (even if it’s) not
visible in code. lit-html takes advantage of that fact and whenever the same template is used, it will only update any
changed expressions.
In the example above each click will only update a tiny piece of the rendered HTML which will keep DOM operations to the
minimum. Even though the times variable is calculated each time, it will only ever be rendered when it actually changes
between renders. Not every time.
So what about declarative UI?
Previously I struggled to bend <template> to suit my needs in pursuit of a declarative solution for defining views
which are dynamically selected based on the content.
First of all, in my current implementation the order in which the templates appear in the page is important for the
order in which the will be selected. In case there are multiple matches.
Secondly, I used Polymer 1.0’s Templatizer which not only disappeared in Polymer 2.0, but it was also
notoriously buggy and hard to master.
With lit-html I will be “freed” from Polymer and likely implement my elements will in plain JS. Additionally it will
be much easier to work with those templates; to extend with ES classes and compose with less custom element on the page.
import{TemplateRepository}from'template-repository';import{render}from'template-selector';import{html}from'lit-html';/*** Will render http://example.com/vocab#Person*/classPersonTemplateextendsTypeTemplate{gettype(){return'http://example.com/vocab#Person';}getcontext(){return{'@vocab':'http://example.com/vocab#'};}gettemplate(person){returnhtml`<h2>${person.name}</h2><divclass="details"><ahref="${person.website}">Mywebsite</a></div><divclass="avatar">${render(person.avatar)}</div>`;}}/*** Will render http://schema.org/ImageObject */classSchemaImageTemplateextendsTypeTemplate{}TemplateRepository.append(PersonTemplate);TemplateRepository.append(SchemaImageTemplate);
The render imported above would select a template from the repository and insert it into the parent template. No need
for nesting <object-view> elements. That is of course if I figure out how to observe changes ;)
Bottom line
I really do like what’s coming with Polymer 3.0. It will embrace ES6 modules, finally. It may be that Polymer will become
more similar to Vue or React but it will still be closest to the Web Platform.
]]><![CDATA[Towards server-side routing with URI Templates (RFC 6570)]]>2016-11-13T23:15:00+00:00http://t-code.pl/blog/2016/11/Towards-server-side-routing-with-URI-TemplatesThere are many MVC frameworks out there and all of them share a common feature - routing. Most libraries use a form of
URI patterns to match incoming requests. On top of powerful features like limiting allowed values to certain types or
by using regular expressions, they all share a common flaw - great simplification of the URI.
There is however a similar proposed standard described by RFC 6570 and appropriately called URI Template
As the name implies, it defines URI patterns which can be then expanded to actual URIs by substituting variables and work
the opposite way by extracting variables from a given URI. This makes it a viable option for matching request URIs on the
server to determine what code to execute, if any.
So what is wrong with typical routing?
In most libraries I have seen routing is declared simply by defining variables as URI segments:
Dancer and Express use a similar syntax and also support regular expressions:
/users/:userId/books/:bookId (Both)
/team/:team/** (Dancer)
/ab(cd)?e (Express)
The features to constrain segments to specific values using regular expression or some custom feature certainly is a
powerful one but there is much more to URL than just segments (not to mention URI in general). The general syntax of an
URL is as follows:
In a web application the scheme will usually be HTTP(S). Let’s also ignore the user/password and host/port which aren’t
usually the concern of a REST server accepting requests. That leaves us with the path, query
and fragment.
Do you notice already how typical routing completely neglects query and fragment?
In my opinion they should be part of it. Why, you ask? Read on!
Using identifiers like you probably should
Query string is part of the identifier
In a RESTful API the identifier is the complete URL. If the client does a request like
1
GET /user?id=123 HTTP/1.1
Why shouldn’t it be possible to include the query string parameter as part of the route? It is after all an integral part
of the identifier. Yet all libraries that I’ve worked with require manual work to extract the value of id in user code.
Segments are so much more powerful
The URI path is a series of zero or more segments delimited by the slash / character. And so an absolute path like
/users/tomasz/articles/uri-template has four segments:
users
tomasz
articles
uri-template
But segments are not necessarily just text. And they certainly don’t have to represent hierarchy of file system folders.
A friendly #RESTful reminder - URL path does not represent file-system hierarchy. Heck, it doesn't have to be a hierarchy at all #hypermedia
A little known feature, which I’ve only just discovered very recently, are parametrized path segments. They work similarly
to query strings:
1
/segment1;param1=val1;param2=val2,val3/segment2
See how segment1 has extra bits attached. As JSON these parameters would be represented as
1234567
{"param1":"val1","param2":["val2","val3"]}
And here’s a practical example. A hypothetical API could serve a resource representing a collection of, say, books:
http://example.rest/books. Another resource could be used to retrieve covers of those books: http://example.rest/books/gallery.
Usually any manipulation of such resource is handed over ot query strings.
So, what if the resource owner wanted to offer a gallery of books cover but only books by Oscar Wilde and only covers in
PNG format. Because why not?
The URL would probably look like http://example.rest/books/gallery?author=Oscar%20Wilde&format=png. Do you also see the
SRP rule being validated? Why not instead use the URL like
And hey! Now it’s possible to just drop the last segment and leave
1
http://example.rest/books;author=Oscar%20Wilde
That looks like a resource containing books by Oscar Wilde. Despite the tweet quoted above, people do love URL hierarchies
right? They probably are quite useful in the end.
And it’s not just about single responsibility of path segments (there probably isn’t such a thing). I don’t have
empirical proof, but I would guess that parametrizing segments could lead to better controller/module/handler design.
So how do I implement that?
Most languages probably have a library out there that implements the URI Template standard. So just go ahead a try to
replace the routing in your favourite Web framework so that it works with RFC6570 instead. The books covers resource route
shown above would become:
1
/books{;author}/gallery{;format}
Isn’t that nice? No query strings lurking in the implementation. Everything clear up front.
My Nancy experiment
I did precisely that and created a proof of concept in Nancy. It’s available on GitHub under
https://github.com/tpluscode/nancy.routing.uritemplates and
hopefully I will make it into a useful library (there are still some issues to sort out).
In the current shape the usage is akin to implementing a typical Nancy application. Instead of NancyModule you implement
UriTemplateModule and replace the RouteResolver with UriTemplateRouteResolver. The actual route definition is just the
same:
Such route will match /books/gallery, /books;author=Shakespeare/gallery and /books/gallery;format=square.
Possible issues?
Have you made that far? Great. Now it’s time to learn about the thorns that this rose has.
Route variable constrains
In the beginning of this post I show how routing in existing libraries allow constraining captured variables using
custom syntax or regular expressions. The URI Templates specification has no such notion neither any extensibility mechanism.
This is not a great deal as far as I’m concerned. It should be possible to replicate the constraining functionality of
Nancy or Spring by extending variable template expressions. The standard does reserve some characters for future use and
they could serve as a separator between the variable name and the constraining expression. For example, to only allow
the page variable of a collection to be an integer the template could be
1
/collection{/page|int}
The pipe character is reserved and as such cannot be a legal part of the expression. As a consequence, a web framework
could reliably separate the page variable from the int constrain.
Route prioritization
This is something I haven’t figured out yet. Nancy, and likely other libraries have the ability to work with multiple
routes matching a given URL. For example routes /page/{title}/{sub} and /page/about/{sub} would both match a
request for /page/about/cats. But because the about segment is an exact literal match in the latter route, that route
would actually be executed. It’s potentially a deal-breaker and I’m eager to find a solution to that problem.
I’m quite convinced that URI Templates should have been used for routing from get-go. To me it seems quite obvious now
that hypermedia is becoming more and more recognized as an important design pattern and URI Templates are an important
part of driving the clients between application states.
Being able to reuse the same technology on both client and server side should be very beneficial to visibility and maintainability
of hypermedia-driven APIs.
]]><![CDATA[Problem Details for HTTP APIs and Nancy]]>2016-11-11T10:00:00+00:00http://t-code.pl/blog/2016/11/RFC-7807-and-NancyThere are a number of guidelines for returning errors from a REST API in a consistent way. Of course, API authors should
use status codes correctly to signify
the result of an action. It is also a good idea to return some error details in resource representation. Some API vendors,
like Facebook or Twitter have come up with their own solutions.
However, there is a Internet Engineering Task Force (IETF) proposed standard called Problem Details for HTTP APIs. It
was created be Mark Nottingham and is described in document RFC 7807. Interestingly
though there is fairly little support in for .NET Web API libraries and none for Nancy 1.x.
Unfortunately there wasn’t one for the stable branch of Nancy, currently at 1.4.3.
Introducing Nancy.ProblemDetails
And so, I have created my own package I called Nancy.ProblemDetails.
It adds support for serializing JSON Problem Details and uses the library Tavis.Problem by Darrel Miller.
]]><![CDATA[Publishing Polymer elements written in TypeScript (with dependencies)]]>2016-08-15T10:00:00+00:00http://t-code.pl/blog/2016/08/publishing-polymerts-elementsI love consuming custom elements but writing them in Polymer with ES5 is far from ideal. ES6 (or
more correctly ES2015) could offer some improvement but it is still not officially supported by the Polymer
team and their toolset.
Thankfully, there is PolymerTS which offers a vastly improved Polymer API, mainly thanks to decorators. It
also let’s developers take advantage of ES6 modules but there is one problem: how do you publish elements with dependencies
both on JSPM packages and other elements from Bower?
TL;DR;
Here are some highlights from this post:
Don’t reference bower dependencies directly to avoid vulcanizing polymer.html
* reference them in package manager-specific entrypoint instead
Inspired by the Taming Polymer post by Juha Järvi, the initial setup involves preparing JSPM, SystemJS and
TypeScript. The original post however, discusses creating apps. Here I will show how to create, publish and consume a
reusable element.
First, bootstrap JSPM by running jspm init. All question can be left with default answers except choosing TypeScript
as the transpiler.
Second, instruct SystemJS to assume ts as the default extension when loading your code. I usually place it in the
src folder and so update config.js file accordingly by adding the packages property for the sources folder.
Lastly, you will need PolymerTS itself and SystemJS plugin for loading HTML files using the ES6 import syntax. They
are installed by running:
123
bower init
bower i nippur72/PolymerTS --save
jspm i html=github:Hypercubed/systemjs-plugin-html
Note that unlike Juha Järvi, I install systemjs-plugin-html from jspm and not bower. It is also crucial that you explicitly
set the name for the plugin by installing with html= prefix. Otherwise bundling, which I explain later in this post, will
not work.
Creating elements
Internal dependencies and HTML templates
Because I’m using SystemJS with a transpiler, each element will be split into separate html and ts files. The HTML will
contain the <dom-module> element but no script. Instead, each of the elements’ code will import the template using the
import syntax via the systemjs-plugin-html plugin. Note the .html! suffix. This is the outline of my <md-ed> element.
Similarly, any shared module or other local elements can be referenced using modules. Above you can see the second line
which imports a behavior.
External library dependencies
With the help of JSPM and SystemJS, your elements written in TypeScript (or ES6 I imagine) can reference virtually any
external library. They can be packaged as AMD or CommonJS modules or as globals. JSPM unifies the module definitions so
that most libraries simply work in the browser.
The example component uses the marked library to parse markdown. It is an npm module
which I install with JSPM as usual.
1
jspm i npm:marked
Now, it’s possible to import the library and use its functionality in the custom element:
import'marked';classMdEdextendspolymer.Base{@property({notify:true})markdown:String;@observe('markdown')_markdownChanged(md){varhtml=marked(md);// do something with parsed markdown}}
External web component dependencies
Most web components are currently installed with bower. This is true for Google’s elements from elements.polymer-project.org
and most I’ve seen on customelements.io. Bower is used because it creates a flat directory structure which allows
for predictable import links. Unfortunately, there is no built-in way for importing such dependencies. Also bundling won’t
work for elements which explicitly import polymer.html. There is currently no way to exclude certain imports from the bundle
which causes multiple Polymers. Needless to say, it is bad.
So, if you need to reference a third party component like some Iron or Paper Elements simply install them from bower but
don’t import them in any of your source files. Instead they will all be imported in an entrypoint - separate for Bower and
JSPM.
Publishing for Bower
Follow the instructions below if you want to publish you element to be consumed from Bower.
Bundling
Bundling is done by running the JSPM CLI which has a number of options. For Bower, I’ve found the bundle-sfx
command works best, because it allows creating packages which require neither any specific module loader
nor JSPM/SystemJS. Elements bundled this way will be possible to consume using bower just like any other element.
I usually add the bundling command to NPM scripts:
src/md-ed - marked dist/build/build.js means that the root src/md-ed.ts file and it’s dependent modules will be bundled
into dist/bower/build.js but will not include the marked library. The marked library will be added later as a bower
dependency.
--format global creates a bundle without any module loaders. This is enough for bower and web components.
Finally, the --globals "{'marked': 'marked'}" switch is required for some excluded modules when bundling. It tells
JSPM what global variable to use when injecting dependencies into your bundled modules.
I’m intentionally not minifying the contents. The consumer will do so when bundling his or her actual application.
Now, running npm run build-bower will create a bower/dist/build.js with transpiled and bundled scripts and bower/dist/build.html
with vulcanized files. Interestingly, the html must exist beforehand, which looks like a bug in the SystemJS html
plugin. Simply create one before running the npm script:
123
mkdir dist
touch build.html
npm run build-bower
Oh, and don’t exclude the dist folder from git. You’ll want to push the bundled files with everything else.
Packaging
Most components published with Bower include a html file named same as the repository (and element). My element is called
md-ed and so I created a md-ed.html file in the root of my repository. This will be the main entrypoint for consumers
to import. Here’s the complete file:
<!-- imports of bower dependencies --><linkrel="import"href="../polymer-ts/polymer-ts.min.html"/><linkrel="import"href="../paper-input/paper-textarea.html"/><linkrel="import"href="../paper-tabs/paper-tabs.html"/><linkrel="import"href="../iron-pages/iron-pages.html"/><script src="../marked/lib/marked.js"></script><!-- import of bundled HTML files --><linkrel="import"href="dist/bower/build.html"/><!-- this is required due to a bug in HTML loader for SystemJS --><script>varSystem=System||{};System.register=System.register||function(){};</script><!-- referencing the bundled, transpiled code of the element --><script src="dist/bower/build.js"></script>
At the top I added bower dependencies. It’s important that the paths don’t include bower_components. On the consumer
side, the elements will already live alongside other bower dependencies. I include all component dependencies and marked,
which I excluded from the bundle. Shall you choose not to exclude some dependency, you would then keep it out of your
bower entrypoint.
Below the bundled files are referenced. There is some additional boilerplate here. The extra script is a remedy for another
shortcoming of the systemjs-plugin-html. It doesn’t play nice with the bundle-sfx command and leaves some references to
SystemJS. This is simply to avoid System is undefined or similar errors.
Finally, you may also want to add the file to you bower.json as "main": "md-ed.html".
Follow the instructions below if you want to publish you element to be consumed from JSPM.
Bundling
Unfortunately, the same bundling command doesn’t work for both Bower and JSPM. I’ve found that for JSPM it is best to
use the jspm bundle command which produces a similar output but for use exclusively with SystemJS and no other module
loaders. The npm script is similar but simpler than the command used for Bower:
It produces a similar output - combined scripts in dist/jspm/bundle.js file and vulcanized dist/jspm/bundle.html. Here
the marked library is also excluded from the bundle.
Packaging
For consumers to be able to use your JSPM package it is also necessary to create a main entrypoint. For that purpose I
created an md-ed.js file in the root of the repository.
The outline is very similar to Bower’s entrypoint:
Import bower dependencies with HTML plugin
Import the bundled HTML and scripts
Load the element from the bundle
The last step is necessary because JSPM bundles don’t immediately load any modules. They are just used to combine multiple
modules in one script.
For the element’s package to be installed correctly, the configuration file must include the main file, similarly to that
of bower.
A perceptive reader will also notice that I’m using ES6 module syntax above. SystemJS can handle this just fine provided the
format option is set in package.json. Here’s mine, with both entrypoint script and the format set.
Publishing a package in ES6 syntax will also enable rescursive bundling of the element’s dependencies. Otherwise JSPM
would not be able to bundle direct usages of System.import. In other words some dependencies would remain unbundled.
Consuming
Consumers, in order to us the element, must install it using JSPM but also install the necessary bower packages. The
easiest seems to be installing the same element from both JSPM and bower. This way, albeit cumbersome when updating,
will ensure that all necessary dependencies are pulled as well. To install the sample element one would eun the two
commands
12
bower i tpluscode/md-ed --save
jspm i github:tpluscode/md-ed
Typically there would be single application module, like app.js, which references all it’s dependencies. For our jspm
component the import would be a simple import 'tpluscode/md-ed'
At runtime, it will pull all necessary files from bower and jspm components. The main index.html file will then reference
the app.js script and uses SystemJS to load the add.
I realize that the presented ideas are far from ideal. The web stack is not yet consistent enough, with its multiple
package managers etc, to support the modern ideas around web components. Until it matures I hope that someone out there
will find my ideas helpful.
And please, if you think my bundling routine can be simplified, do leave me a note in the comments.
]]><![CDATA[Lest I forget: International Conference on Web Engineering - Day 2 Research Tracks]]>2016-06-19T22:45:00+00:00http://t-code.pl/blog/2016/06/ICWE-2016-day-2Earlier this week I shortly wrote about the first day Research Track at International Conference on Web Engineering
which took place between June 6-7. Today it’s time for day 2 (keynote included).
Day 2
The second day ended with a lovely dinner in the restaurant and lookout point atop Monte Brè. Although the weather
was a little flaky, everyone got a chance for some pictures of Lugano from above. Here’s my panorama shot of Lugano:
Other than that, unsurprisingly, the conference research track featured a whole lot of interesting lectures, ideas and
showcases.
The keynote - Microservices - The Hunting of the Snark
James Lewis of ThoughtWorks (yes, the one famous for Martin Fowler)
gave and extensive and wildly interesting talk about the state of Microservices, organizational challenges for companies
which want to try and also consultancy work at banks. As we all know, a picture is worth a thousand words, so here are
some tweet highlights from the keynote
"how big are they" doesn't matter for #Microservices; what matters is how many you can handle. do you have a plan? @boicy at #icwe2016
REST APIs: A Large-Scale Analysis of Compliance with Principles and Best Practices
Unfortunately, this one I didn’t enjoy as much. Florian Daniel showed their results
of a large scale analysis of mobile data usage around Milan. The team gathered 78 GB worth of data and calculated a number
of metrics like HTTP method usage, media types, user agents and more. An intriguing idea, but without interaction context
it is really hard to come to any conclusions about the “quality” of any single endpoint from REST perspective. Not to mention
that the dataset likely misses any encrypted traffic, which I would expect to be a significant portion. If anything, the
work is an analysis of HTTP protocol usage on the mobile web, but not really REST at all. This is quite evident when you
look closely at some of the metrics, most of which revolve around the URI (eg. presence of underscores, api in path,
presence of a trailing slash, version in URI). I find it very harmful to consider anything specific about URIs a REST
principle and best practice.
A similar presentation followed, in which Erik Wittern presented the results of a daunting benchmarking of a
some popular public APIs including Twitter and Flickr, but also less popular services like police.co.uk. It was very
entertaining to see how wildly some APIs differ when requested from different regions and at various time of day.
Of course one could argue that such comparison is a bit unfair. For example the aforementioned police.co.uk is likely not
intended to work smoothly from Australia but on the other hand it may of interest to someone anywhere on the globe occasionally.
The authors are aware of limitation to their method but rightly point out that it is very important to plan for availability
when designing a public API. Especially that every single tested service showed occasional peaks in latencies and even
outages.
MIRA: A Model-Driven Framework for Semantic Interfaces for Web Applications
Next presentation that really got my attention was Daniel Schwabe’s presentation of MIRA, a JavaScript tool
and RDF notation for modelling user interfaces with abstract elements, so that they can be replaced by concrete elements
on a given platform. This method addresses the volatility of the web and the shortcoming of responsive design, which will
soon be unable to cater for futuristic User Interfaces.
MIRA authors also boast their results which show that for seasoned programmers and non-developers alike it took the least
time to build a simple application using their tool. However we’ve seen that already, which makes me skeptical (I’m looking
at you Lightswitch!).
This was another slight disappointment of that day. Darian Frajberg presented their evaluation of using various techniques
to manage volatile functionalities of an application. An example is a time-limited prices reduction on certain item on an
e-commerce platform. The problem there is that programming tools such as code weaving and regular expressions, which were
the basis for their platform are very demanding on the programmers. Even when packaged as a reusable library, such a library
would take a great effort to support and evolve. Also, the authors didn’t really compare their results to real methods
used in practice. The baseline for their evaluation included naïve and unrealistice methods, which would not be used in
serious software.
This very unassuming and slightly misleading title hides an exciting piece of software called Web Objects Ambient.
It is a Firefox extension (with a Chrome version a possibility) which allows end users to enhance web content by interacting
with elements and combining it with more data like tweets, reviews, etc. And it uses DBpedia as the source of concepts .
In case I somehow failed to convey the general idea, here’s a video showing WOA in action.
Finally, there is also an extensibility model, which allows
developers to extend the sidebar seen above with more powers!
Because RDF Streams are above me I’m skipping right to the last presentation of the day. Awarded the Best Vision Paper Award,
the vision by Istvan Koren and Ralf Klamma ongoing effort to build a distributed End User Interface for
the Web of Things. Build with Polymer and their own peer-to-peer communication library! Again, because a picture will
explain uch better than words, here the slide showing an overview of the authors’ vision.
]]><![CDATA[Lest I forget: International Conference on Web Engineering - Day 1 Research Tracks]]>2016-06-13T22:45:00+00:00http://t-code.pl/blog/2016/06/ICWE-2016-day-1This past week I took part in the International Conference on Web Engineering or ICWE for
short. I’d like to round up the lectures I attended, demos I watched and posters I saw. While I still remember, I want to
write about my impressions about each individual one, at least at the very shortest. Of course I won’t be able to cover
it all, because I wasn’t able to attend every session for obvious reasons and at the same time I didn’t find everything
equally interesting. I’ll do my best nonetheless.
Day 1
Throughout the three conference days I mostly attended the Research Tracks. They contain a whole lot of knowledge, new ideas
and ingenious tools. Here’s what caught my attention on the first day.
The keynote - Quo vadis Google Knowledge Graph
The conference started with a talk by Xin Luna Dong
about the Google Knowledge Graph. It was very interesting to see how Google employs a data model similar in concept to
RDF to build it’s massive knowledge base, how Freebase is currently being replaced by Google Knowledge Vault and
learn about (Lightweight) Verticals, which are one how Google collects its data. However, as one listener points out:
#ICWE2016! Nice presentation by Luna Dong but... where is Wikidata?
This interesting work by Linda Di Geronimo, Maria Husmann, Abhimanyu Patel, Can Tuerk and Moira C. Norrie
was awarded the Best Paper Award for good reason. During the talk we could watch what great interactions can be achieve
by communicating multiple mobile device equipped with accelerometers. That has some proper SCI-FI potential. And just thing
about all the games. Well, unfortunately we’ve heard that lagging would be too great for dynamic real-time interaction,
but some less intensive activities? After all we all have a universal Wii-like controller in our pockets. It just so happens
that it can take calls.
Revisting Web Data Extraction using In-Browser Structural Analysis and Visual Cues in Modern Web Designs
In his presentation, Alfonso Murolo showcased his Chrome extension called DeepDesign, which uses some
state-of-the-art techniques to aid extracting (scraping) data from websites. The extension takes advantage of structural
and visual cues to automate the creation of wrappers for extracting data from web pages. I only wish that the extension
was made public and included a crawler so that entire websites can be scraped. Currently it requires manual action.
Unfortunately, currently trying DeepDesign won’t be possible.
Clustering-Aided Page Object Generation for Web Testing
First day, and yet another award - for best student paper. In this presentation the audience was introduced to APOGEN
or Automatic Page Objects Generator. It is a Java tool, which crawls a website to create Page Objects for its pages.
However it does by combining multiple instances of the same page into clusters. It allows correcting these clusters with
a simple UI. That UI even shows small renderings of crawled pages. There is so much usefulness in this tool and it is
already available as open source (just why SVN?).
How cool is that? If I ever hear that scientific conferences don’t have anything practical offer to I will slap that
person across their face .
QwwwQ: Querying Wikipedia without writing queries
This is another cool Chrome extension I’m very excited about, which unfortunately is not available publicly just yet.
QwwwQ (pron. quick) is an ingenious tool for querying DBpedia in a way I would describe as a mix of
query-by-example and maybe faceted search. It would allow non-technical users to explore the wealth of data stored on
wikipedia and also help developers build SPARQL queries for DBpedia with a nice GUI instead of a text editor. In their
paper the authors (Massimiliano Battan and Marco Ronchetti) mention future plans for allowing JOIN
operations to traverse relations. I would add to that list the possibility to retrieve the underlying query for further
customization.
What I found most interesting is that QwwwQ cites a 1975 paper A psychological study of query by example by John C. Thomas
and John D. Gould. Isn’t that cool?
Aspect-Based Sentiment Analysis on the Web using Rhetorical Structure Theory
Another award that day - Distinguished Paper Award. Although the topic is quite advanced, the presenters succinctly explained
their application of Rhetorical Structure Theory or RST in
deriving sentiment from product reviews written in English. What does it mean? It means that by deconstructing and
classifying parts of a review multiple algorithms devised by the authors can determine what positive and negative sentiments
the reviewer expressed. Interestingly, the results are slightly worse for negative reviews (allegedly, because positive
words are often used to express negative sentiments) and results are better for reviews consisting of multiple sentences.
Diversity in Social Media Urban Analytics
An fairly interesting paper, which shows how social media activity data (from Twitter and Instagram in this case) can be
used to determine patterns of their respective users in cities. The authors analyzed the usage of said social networks in
four European cities: Amsterdam, London, Paris and Rome. Among the findings the authors discovered that
Instagram users concentrate more in the vicinity of tourist locations
The same can be said for tourists as opposed to residents
Instagram shows more uniform activity over time in various cities that Twitter (for example Amsterdam Twitter activity dies out much quicker in evenings)
Both social networks’ activity is proportional to city size
The activity of people aged 45+ is very low
As unsurprising as they may seem, these results are not really meant to reflect the reality in 100%. The authors are aware
of the challenges and acknowledge shortcomings of their techniques. This paper is however a good exploration of various
possibilities which await a data scientist who is interested in analyzing social behaviour on the web.
Another work with so much potential for practical application. Long ago I have been looking for a good, open source
alternative to Stack Exchange. It turns out that there is one such open-source project being developed at Slovak University
of Technology in Bratislava. Its focus is on educational use and has unique features for teachers/students and integrates
with edX and MOOC. It is also used on the University in Lugano.
Oh, and did I mention that it is open source and hosted on GitHub? Go give it a
try.
]]><![CDATA[Interesting JavaScript quirk when accessing object with index]]>2016-05-15T20:20:00+00:00http://t-code.pl/blog/2016/05/indexing-object-with-arrayI’ve just discovered an interesting JavaScript quirk which I haven’t seen before. It turns out that indexing an object with a single
element array has the exact same effect as indexing with that array’s element.
JavaScript just doesn’t stop amazing developers. There are many quirks I’ve seen, known and exploited. I was so surprised to hav
found one that I’ve never seen before. It turns out that accessing object as an associative array works not only with the actual
index but also when a single element array is used for index.
Of course, the array with two elements returns undefined as expected.
What is even more insane, is that the array can be of any depth as long as it is a single element array within a single element array
within a single element array etc. How weird is that?
Digging deeper, I discovered that it is possible to index an object with arrays on any dimension and that would be equivalent
as indexing with the elements joined with a comma. Here’s a demonstration
Again, it does not matter whether the array is deeply nested inside other arrays
I imaging this can actually be quite useful though I’d be afraid that programmers not familiar with this trick would not understand
what is happening.
A superfluous google search didn’t answer why this works like that. A comment with an explanation will be greatly appreciated .
]]><![CDATA[Consuming hypermedia - declarative UI]]>2016-04-30T22:25:00+00:00http://t-code.pl/blog/2016/04/hypermedia-driven-uiI’ve been going on about hypermedia for a long time now. I’ve touched both client and server side in terms of processing
resource representations. There is however a big missing piece in how developers should build user interfaces. Personally
I have been hooked on the idea of Web Components and I’ve had some success experimenting with using a declarative
way for defining User Interface building blocks.
Declarative views for resource representations
Assuming the use of RDF (Resource Description Framework), the user interface can be defined by creating a template
for given RDF class or data type. A few examples can include: a dedicated custom element for displaying a person,
a lightbox element for images typed as schema:ImageObject or custom datepicker for xsd:date.
My idea for such syntax is to extend the <template> tag so that whenever it is added to DOM, it somehow registers itself
for use in specific case. Because the template tag itself is quite dumb I would take advantage of Polymer data
binding features and Polymer.templatizer so that developers can define dynamic templates.
At the top level, I envision a generic <object-view> element. It would inspect the given resource and choose among the
available specialized or generic templates (see further down).
<object-viewid="top-view"></object-view><script>varobjectView=document.getElementById('top-view');objectView.object={"@type":"http://example.com/vocab#Person","@id":"http://example.com/tomasz","http://example.com/vocab#name":{"@value":"Tomasz Pluskiewicz"},"http://example.com/vocab#website":{"@value":"http://t-code.pl"},"http://example.com/vocab#avatar":{"@type":"http://schema.org/ImageObject","http://schema.org/caption":{"@value":"Me in Kraków"},"http://schema.org/contentUrl":{"@value":"http://example.com/tomasz/avatar-large.jpg"},"http://schema.org/thumbnail":{"http://schema.org/contentUrl":{"@value":"http://example.com/tomasz/avatar-small.jpg"}}}};</script>
By setting the objectView.resource property the element would then look for template dedicated to the ex:Person class
(example ):
See the <object-view> used again for person.avatar? This way it would be possible to create composable user interface
with specialized building blocks. Here’s how a template for schema:ImageObject can be rendered as a kind of a lightbox
(example ):
Further extensions could introduce new ways for selecting a template based on the resource content, based on the predicate
(for example to use different template for property ex:husband vs property ex:wife) or to be able to create templates
not only for resources but also for literals (for example to select templates based on language tag?)
Common elements for Hydra Core types
Building on top of the API above it would be possible to created predefined common elements for Hydra Core resources
returned by heracles. The most obvious idea is to build a reusable template for a hydra:Collection:
1234567891011121314151617181920212223
<!-- first template for collection elements --><templateis="resource-view-template"type="https://www.w3.org/ns/hydra/core#Collection"as="collection"compact-with="http://www.w3.org/ns/hydra/context.jsonld"><templateis="dom-repeat"items="[[collection.member]]"as="member"><object-viewobject="[[member]]"></object-view></template><divclass="pager"><object-viewobject="[[collection.view]]"></object-view></div></template><!-- views can have specialized templates --><!-- the current spec defines the PartialCollectionView type --><templateis="resource-view-template"type="https://www.w3.org/ns/hydra/core#PartialCollectionView"as="view"><ahref="[[view.first]]">First</a><ahref="[[view.previous]]">Previous</a><ahref="[[view.next]]">Next</a><ahref="[[view.last]]">Last</a></template>
See how again the <object-view> is used to delegate the decision on what template to render.
Obviously real life Hydra templates will need to be much more sophisticated. Template for hydra:PartialCollectionView
would definitely want to hide unnecessary link. Template for hydra:Collection would likely display a different view for
collection member from the view displaying the same object outside a collection. This could be a feature of the <object-view>
element though.
Distributing templates
Finally one wouldn’t want to declare these templates every time in an application. I imagine that a package containing
reusable Hydra Core elements would be simply wired up by a single element:
123
<!-- drop this on a page, and the above templates would be --><!-- available for <object-view> elements --><hydra-core-templates></hydra-core-templates>
Similar element could be offered by data publishers somewhat satisfying the REST’s code-on-demand constraint.
It is unclear however how it would be possible to customize behaviour of those templates/elements. Overriding the selected
template could be an easy way out though…
]]><![CDATA[Third labour of hypermedia - extensible media types]]>2016-04-24T16:00:00+00:00http://t-code.pl/blog/2016/04/hypermedia-must-be-extensibleMost hypermedia media types like HAL or SIREN are some sort of extension of JSON, which is understandable.
JSON is a natural choice because it already is the most common data interchange format for APIs. However JSON as syntax
is by design simple and it doesn’t support vital part - links. To plug that hole these media types are intrusive in
that they impose a very specific structure of documents. Instead of extending the meaning of representations they hijack
the syntax and structure.
Personally I’m biased towards Hydra Core Vocabulary because, unlike all other I have come across, it is based on
RDF. Why is it important?
Extending JSON creates rigid structures
Consider this sample from HAL specification website (excerpt).
What is all that business with _links and _embedded? Also would you prefer to serve or consume XML for some reason?
Well, that will not be possible because most other media types above, except Hydra, HAL is JSON-based. Hence the need for
that convoluted document structure.
JSON also suffers from another deficiency - key ambiguity. It would be very easy to bump into clashes if we were to enrich
such representations with custom extensions.
RDF is not syntax
I wrote that Hydra Core is RDF-based. Unlike JSON RDF is a standard way to describe data structures and not syntax. It is
possible to write the very same piece of data in a multitude of ways yet still retaining the exact same meaning. First
there are n-triples. Let’s state that my name is Tomasz and my friend can be downloaded from http://t-code.pl/tomasz/friends.
As you see almost everything is an URI. This solves the ambiguity problem. This is however very verbose and redundant and
will waste a lot od bandwidth for large response. Fortunately there are other media types, which can represent the same
information in different form. There is the compacted flavour of n-triples called Turtle and it’s similar twin
Notation3.
What Hydra core does is essentially extend the data (not the syntax) with various hint for the clients so that they
can discover how to perform more requests. For example let’s add a hypermedia control stating that the above resource
<tomasz> can be updated with a PUT request.
You could still convert this between various RDF serailizations and retain the meaning!
For a Hydra-based API to be complete there must be a lot of information provided by the server. The above is the tip of
the iceberg. The body of the described PUT request must conform the definition of the http://t-code.pl/api#Person type.
But where is this definition? And how detailed can this definition be?
Hydra core is served as a runtime API documentation, linked with a specific Link header relation. This documentation can
contain a number of simple definitions such as required fields, expected data types etc. It can also be extended so that
clients aware of the extension can adapt better to the API. For example a server can annotate a field as being a password,
so that an appropriate control is presented on the website.
This is where the first really big hurdle stands.
Where are these aware clients? And where are the servers?
We need the tooling
I’ve started creating both a server and client tools to produce and consume Hydra-based hypermedia. The server side is
implemented as a .NET Library for Nancy called Argolis. The client side is a JavsScript library called
heracles. I’m also experimenting with a way to produce a dynamic yet customizable UI with Web Components.
I will be showing usage examples and discussing ideas in future blog posts.
]]><![CDATA[The labours of hypermedia]]>2016-04-24T15:40:00+00:00http://t-code.pl/blog/2016/04/labours-of-hypermediaGoing full-on with hypermedia takes some preparations and to convince the masses will require some tooling and examples.
Especially tooling. The ability to produce rich developer experience is the determinant of many successful technologies.
Another crucial factor are real-life uses cases solved by the technology in question. I would like to focus on the former.
As much as the industry has bought into lightweight Web APIs, often inappropriately called RESTful, there has been an uphill
battle to have real hypermedia gain traction.
Why hasn’t hypermedia gone mainstream?
I’m still not sure what are the main factors which contribute to the slow adoption of real, unadulterated hypermedia. It
seems that a lot of people find hypermedia hard. Just look at all those question on StackOverflow. There are also a number
of proponents of pragmatic REST. In my opinion that mostly means throwing the baby out with bath water. Pragmatic approach
to REST is seen everywhere.
A slightly brighter shade of pragmatic REST are the various media types, which actually do put the emphasis on runtime
discoverability. This is not something I will disagree with. Not every API is made equal and not every media type needs
all the features necessary for a complete hypertext-driven interaction. With links to begin with (think HAL),
through forms (supported by Collection+JSON for example) all the way to rich (SIREN or NARWHL)
and extensible (Hydra Core) hypermedia.
An optimistic person could envision a proliferation of cool media types and servers using them. Is this so far from the
truth! I think that there are still a number of puzzles missing which hinders adoption of proper hypermedia.
The labours of hypermedia
Hypermedia has still a long way to go. To make it happen for real there has to be an active community which understands
its benefits and will produce all the necessary moving parts.
We must raise awareness of the benefits of hypermedia
We must define best practices around the shady parts of REST such as versioning
We need powerful and extensible media types
We must create the tooling around these media types for both server and client side
We need a new paradigm for creating adaptive user interfaces both of autonomous and bespoke clients
In future posts I will try to address these labours and show some of my recipes for actual hypermedia-ness.
]]><![CDATA[Heracles resources vs JSON-LD compaction - enumerable js properties]]>2016-04-20T08:45:00+00:00http://t-code.pl/blog/2016/04/heracles-compacting-resourcesIn my previous post I presented the first incarnation of Heracles, the Hydra Core
client library. While trying to replace my makeshift client I’d implemented for an in-house training project at PGS
I quickly decided that I’m going to need a way to compact my resources. It wasn’t that hard but there was one simple
hurdle to overcome.
TL;DR; with Heracles you can do this:
1234567
Hydra.Resource.load('http://my.api/my/resource').then(res=>{returnjsonld.promises.compact(res,context);}).then(compacted=>{// do something with the compacted resource});
URI properties are a nuisance
Just as in heracles, in my proof of concept code I too mostly worked with expanded JSON-LD objects. This has the downside
that any time I needed to access the properties full property identifiers must be used. Also it is not possible with
Polymer to use the indexer notation for declarative data binding:
12345
<!-- Such markup is not valid data binding syntax in Polymer --><span>{{myObject['http://xmlns.com/foaf/0.1/name']}}</span><!-- Databound object's properties must be accessed with the dot notation --><span>{{myObject.name}}</span>
This is precisely what JSON-LD compaction algorithm is for. It translates URI keys in a compacted JSON object. This
translation is defined in a @context object.
There are many tricks up compaction’s sleeve, which can help turning ugly JSON-LD into a digestive form. Have a look at
this presentation by Markus Manthaler for some more examples.
My code before
In my code I used compaction to get rid of long URI keys so that I can take advantage of Polymer’s data binding without
verbose methods like computed properties or wrapping the object in a view model class.
This is simple, the jsonld.js library takes care of the heavy lifting and produces a compacted object which is data binding
friendly.
Enter heracles
How is this relevant to the heracles library? In my previous post I showed the Operation type (and other parts of the
ApiDocumentation classes) can be compacted so that working with them is easier.
Resources however are a little different. They are always returned expanded and thus should be ready for being compacted.
I was surprised to see that jsonld.promises.compact throws a stack overflow error. The reason is that JSON-LD algorithms
are not designed to work with cyclical object graphs. It simply loops until the call stack runs out.
The Resource class
In my code I have this PartialCollectionView class (excerpt):
See the collection getter? This is where I had a cycle (collection -> view -> collection …). There was also another
cycle inside the apiDocumentation getter in the base Resource class. There are actually two thing going on here. The
first and obvious culprit is the private field. Of course this is just TypeScript sugar, because it will become just a
typical field in the compiled JavaScript. JavaScript has no such notion of private members.
Solution
The first step was to get rid of the field. There is no perfect way to do that but a friend of mine sent me this post,
which presents the use of WeakMap as a possible solution. With that I changed my code so that it no longer contains
unwanted fields. (actual code is actually a little different but you get the drift)
Unfortunately the compaction algorithm still entered the vicious cycle and failed. Why is that? Because enumerable
properties. jsonld.js iterates over the object using simple for (var i in obj) loop, which also
returns all getters by default. One way is to use the native Object.defineProperty method instead of ES6 get x()
syntax but it breaks TypeScript code analysis and generally smells. There is a better way though.
Solution part two
Luckily TypeScript has the decorators and there is a decorator, which does precisely what I wanted. Instead of writing
Of course this will still fail if there are actual cycles in the object graph. I’m hoping though that it won’t be the
case all too often. And for the rare occasion a library like circular-json can be used as suggested in this github
issue. It will make sure that there are no reference cycles. Unfortunately it is a only replacement for
JSON.stringify and so to use it with jsonld.js it’s necessary to deserialize and serialize every time: