
Introduction to Dydra, the Cloud-based RDF Store
For anyone interested in the Semantic Web, data storage continues to be an issue. Although there is a fair number of triple- and quadstore, your mileage may vary. Some triple stores offer mediocre performance, there are stability issues, missing features or unsupported platforms. There however one simple, but hassle-free alternative in the cloud.
In the beginning there was file
As I wrote, I am a keen collector of any printed, public transport-related material such as promotional brochures and books.
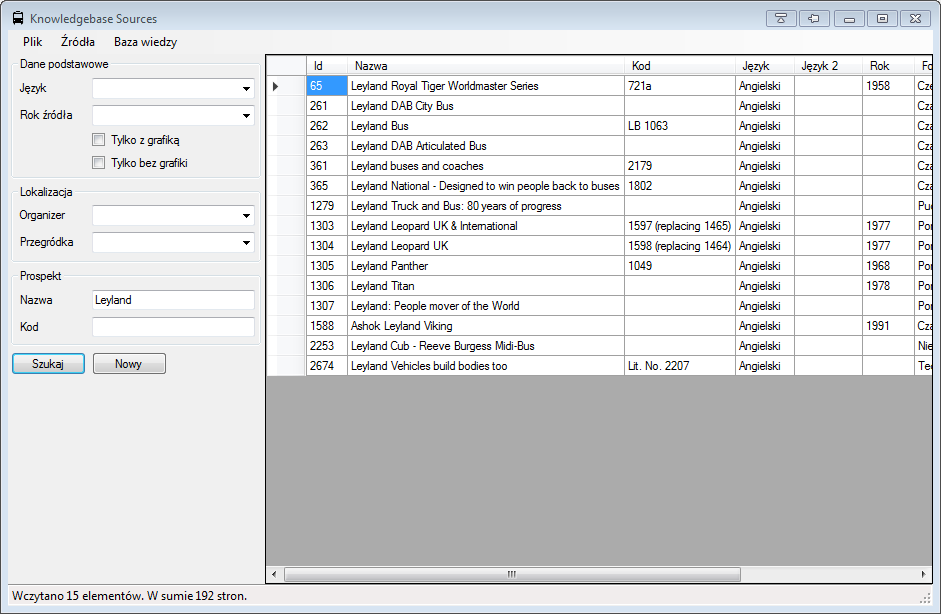
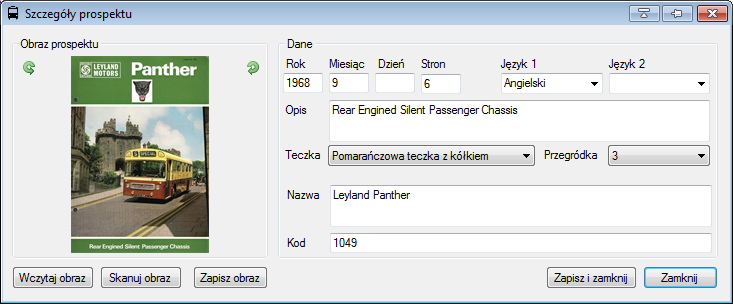
I’ve created a small tool, which helps me manage my collection. It was crucial for me at some point, because it had happened
more than once that I bought another copy of something I already had ![]() . With the tool I can scan and import the
cover and input some basic data about my collection.
. With the tool I can scan and import the
cover and input some basic data about my collection.
Default and obvious choice at the time was SQL Server. Now however, lured by the glorious vision of Linked Data I intend to publish my collection (and other, real wikibus stuff later) as RDF. Thus I convert my tables from relations to graphs using R2RML - that I will also expand upon in another post. But because my experience with triplestores was rocky at best, I decided to keep the small dataset (roughly 20k facts) in a file. That would be generated at first application start and loaded to memory for querying.
Of course that’s not a perfect solution and so I recalled that out there a free, cloud-based triple store exist.
Welcome Dydra, the data tree

Dydra signup page says that invite code is required to create an account. It doesn’t mean that another registered user
is required. It simply means that an invitation request must be sent, before one can register. I didn’t have high hopes
but to my pleasant surprise, I got my code within two days. ![]() .
.
Interestingly, Dydra is completely free of charge. A paid service is available, but on a case-by-case basis as far as I can tell.
Creating a repository
Dydra hosts their files somewhere over at Amazon ![]() , and user’s data is split into virtual repositories. Upon
logging in for the first time in I can create on straight away and then import some existing data. I imported my converted
triples.
, and user’s data is split into virtual repositories. Upon
logging in for the first time in I can create on straight away and then import some existing data. I imported my converted
triples.
As you see above, a repository can be assigned various levels of privacy between completely private to visible to anyone.
Unfortunately, what looks like a bug to me, a public repository can not only be viewed by anyone but also modified.
Beware ![]()
Accessing Dydra repositories
Dydra repositories are accessible over standard SPARQL endpoints and can also be downloaded in various RDF syntaxes. Simple.
Private repositories can be access by using a number of authentication options ![]() .
.
SPARQL Online
Lastly, Dydra has this cool little feature they call views, which can be used to create canned queries. Those queries can
then be accessed over the web in a number of formats. If only they allowed input parameters ![]() .
.
Go Dydra!
I must say I like Dydra pretty much. There may be minor issues, like not using https by default and problems
I mentioned above. However all in all it’s a very simple yet powerful solution. Did I mention it’s free? ![]() I remains
to see how performant the repositories are and how quick the team responds to support issues.
I remains
to see how performant the repositories are and how quick the team responds to support issues.
Usage with .NET
I’m using dotNetRDF and with the SPARQL endpoints it works like charm.
1 2 | |