
Testing APIs Hypermedia-style
One would expect the task of (REST) API testing to be a well-researched subject. After all, REST has been formulated over a decade ago and the number of APIs being built keeps growing exponentially. Yet, it seems that the art of testing APIs hasn’t changed much from the approaches used in testing RPC-style APIs or non-API code.
In this post I’d like to propose a different approach to defining and executing tests of a truly RESTful, hypermedia-driven API.
Recap. What is a Hypermedia-driven API?
The Hypermedia REST constraint, originally called Hypermedia As The Engine of Application State by Roy Fielding, is probably
easiest to grasp through the maxim follow your nose. It means that a client should base the subsequent state changes
(server requests) solely on information gathered from previously received resource representations. The information
available depends on the media type being used. Different media types may provide a different degree of hypermedia support.
The facets have been gathered by Mike Amundsen in his H Factor measurement model.
For example, the simple but popular media type HAL supports links, which lets clients follow them without a priori knowledge about specific URLs. All they need to know is a link relation name, and look for that link in the resource representation. What’s more, the links can appear and disappear in said representations based on resource’s state or the user’s permissions. An adaptive client should only follow links which are present at the given moment.
More sophisticated media types would also provide forms, such as <form> in HTML, which allow clients to perform requests
with methods different than GET to change the state of resources.
Problem with existing testing tools
There are multiple popular tools used for testing APIs. Some of the names include Postman, REST Assured, Karate or SoapUI. Each one of these tool has their respective strengths and characteristics, but they all share a similar flaw: they revolve around URI of individual resources and test them in isolation. While it may sound good from a unit testing perspective, it’s pretty obvious that API tests will always be integration tests. Focusing on a resource identifier prevents the tests from taking advantage of rich hypermedia controls. Those cannot be easily tested, even if the API under test uses a hypermedia media type. Such tests will mostly only reach level 3 of Richardson Maturity Model.
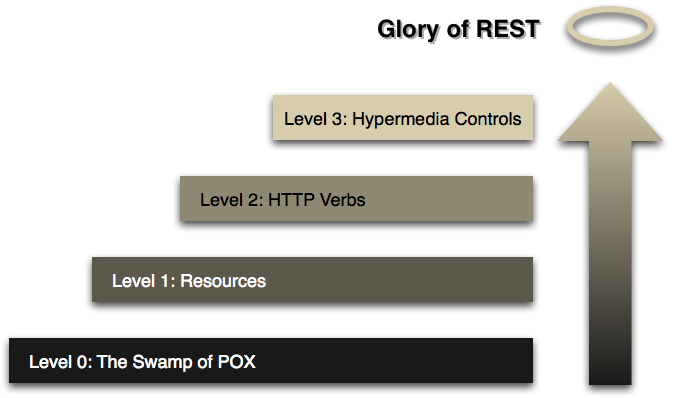
Test by following your nose
To overcome this problem I propose a different approach to building an API test suite. Most importantly, the test executor must act just like a hypermedia-aware client. It should only ever follow links and submit forms found in received resource representations. It also should never begin testing from any random URL because a REST API should only ever advertise just a single stable home URL.
Thus, a test scenario must begin with requesting the aforementioned initial resource and making its way through other
representations via links and forms. I call this What you GET is what you test which would be abbreviated WYGIWYT,
taking after the ancient web development acronym.
WYGIWYT DSL
To make this approach I propose a completely new DSL, or domain-specific language, which can capture the nature of transitioning between resource representations.
The most basic building block would be to define expected hypermedia controls at the root of a test definition. Such top-level (or ambient) declaration would be eagerly executed whenever it is encountered in any resource.
For example, the below snippet could instruct the runner to follow every author
link and assert that it responds with a 200 HTTP status code:
1 2 3 | |
In more complex scenarios, such as involving creating and removal of resources, a nested structure would help build a sequence of related requests. Here’s how I imagine a complete workflow:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
This is just a pseudocode draft but the intention is to keep a clear structure which should read like natural language. This example should be interpreted as:
- When you find a
Personresource, remember its identifier asperson - If it contains an
addFriendform, submit it with a given body - Check that a resource has been created and
GETit by following theLocationheader - Verify that it has been created with certain properties
- Use the
deleteform to remove that resource
Some notes on the DSL
It is clear that media types are not made equal. They also use various names for similar concepts (eg. form vs operation
vs action). While the initial version will focus on Hydra, the DSL should become customizable to
allow plug-in support for other specific media types.
Individual runners would also need to implement media type-specific ways for discovering the hypermedia.
The DSL will then be compiled to a JSON structure, which shall simplify the implementation of runners.
Next steps
We are starting to build the DSL with Eclipse Xtext and generators with Xtend. Those are very mature DSL tools, probably the most sophisticated out there.
Work has also commenced on prototyping a runner targetting Hydra under https://github.com/hypermedia-app/hydra-validator/.
Related research
There seems to be just a handful of research papers and even less development going on around testing hypermedia APIs. The problem with research papers is also that most of them don’t really produce concrete, runnable tools. The only one that does from those mentioned below, is apparently not available for download.
A fairly recent library exists, called Hyperactive. It crawls an API to check that the links are not broken between resources. Unfortunately it is essentially just that, a simple crawler.
A similar paper has been published in 2010 titled Connectedness testing of RESTful web-services by Sujit Chakrabarti of Bangalore. The approach the authors take is quite similar to the proposed DSL. The downside, shown also in the papers I mention below, is that it seems to be tightly coupled to URL structures and specific implementation details, such as HTTP methods. Our approach differs in that it should rely more on the hypermedia control rather than out-of-band information.
Another, quite promising paper is Model-Based Testing of RESTful Web Services Using UML Protocol State Machines by Pedro Victor Pontes Pinheiro, André Takeshi Endo, Adenilso da Silva Simão, published in 2013. Instead of DSL, UML diagrams are used to build the interaction paths. Other than that it seems that the proposed tool (I could not find the code) has some good features, including coverage. The presented approach does not seem suffer from the problem of hardcoding URLs, etc.
There’s also Formalization and Automated Verification of RESTful Behavior by Uri Klein and Kedar S. Namjoshi which unfortunately is exceedingly scientific, as the name rightfully implies, riddled with cryptic mathematical-esque formulas.
Finally, 2017’s Towards Property-Based Testing of RESTful Web Services by Pablo Lamela Seijas, Huiqing Li and Simon Thompson proposes an Erlang-based DSL. Unfortunately the resulting syntax is hardly welcoming, and the approach in general is again in opposition to hypermedia controls. The shown examples are limited to JSON and revolve around URIs and hardcoded HTTP methods.