
REST Misconceptions Part 4 - Resources Are Application State
This part four (0-based) of my series about REST, the mistakes people often make and some ideas of mine. This post on talks about taking advantage of resource representations in a javascript client. This is somewhat related to my other REST post, where I argue that when resources are properly identified and actually linked is should be possible (and beneficial) to ditch client URL routing.
In this series:
- Introduction
- Misuse of URIs
- Not linked enough
- Leaky business
- Resources are application state
- REST “documentation”
- Versioning
Resource-based UI
How do client applications decide what view to present? Most commonly used tool is a router, in which developers define URL patterns and their respective views/controllers/etc. I think this is a terrible idea. Instead I think we should be reusing the resource identifier whenever possible so that (part of) it becomes the client’s address. Period.
Simplest thing would mean stripping part of the resource identifier and putting it in the address bar:
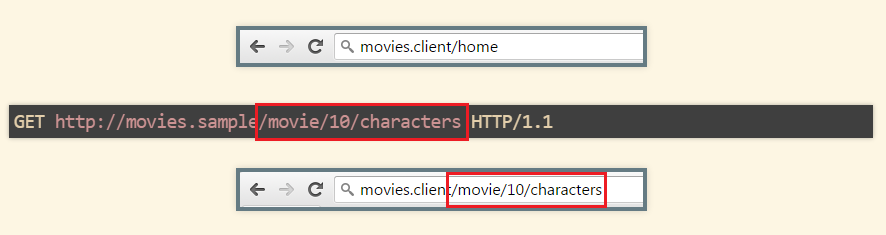
And what if the address is not user-friendly? Add a permalink to the representation. There is even a very appropriate link relation:
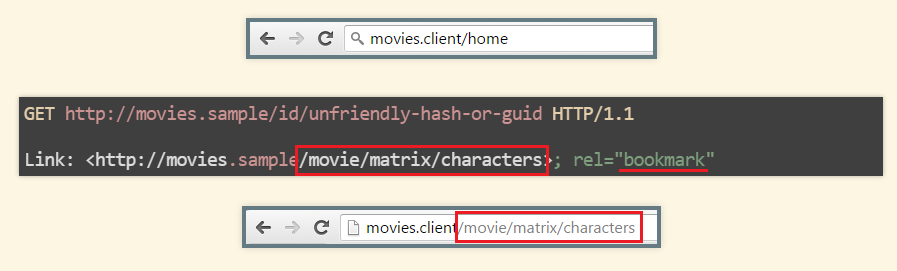
Of course this is just a demonstration of a general idea. In a real system the user interface would likely be presenting multiple resource representations and so a complete solution should take that into account.
Selecting views
Now, the view could also be selected based on the resource currently being displayed. A big problem with the routing approach is unexpected data. What happens when the server returns some representation, which doesn’t ‘fit’ into the view mapped to the given route? A description of an error is one example. Of course, the client will have to take appropriate action and that means more (repeatable) code to maintain.
Instead why not include enough information in the representation so that the client can decide what to render? You serve representations of books - make it clear in the representation.
1 2 3 4 5 | |
I added a type relation, which the client will use to render the UI accordingly. How it is done is irrelevant and there likely are a number of possibilities like view template file conventions or a declarative web component.
(No) Warning: There be no dragons
Some reader familiar with the work of Roy Fielding may be familiar with what he wrote about typed resources:
A REST API should never have “typed” resources that are significant to the client. Specification authors may use resource types for describing server implementation behind the interface, but those types must be irrelevant and invisible to the client. The only types that are significant to a client are the current representation’s media type and standardized relation names. [Failure here implies that clients are assuming a resource structure due to out-of band information, such as a domain-specific standard, which is the data-oriented equivalent to RPC’s functional coupling]
However it does not apply in this context, because the meaning of typing is different. In an RPC style API a typed resource would mean that the client can expect a resource to show certain properties of behaviour. This is not the case. The type can be viewed simply as another property, whose meaning does not allow to draw any conclusions about the resource itself. To put it differently, the type I’m writing about would be viewed as the type of representation and not the resource in it’s programming model sense.